본 포스팅은 Abraham Silberschatz 저 『Operating System Concepts』(9th Edition)의 내용을 개인 학습 목적으로 요약·정리한 글입니다.
5.1 기본 개념
-
하나의 CPU는 한 순간에 오직 하나의 프로세스만을 실행할 수 있다.
- 메모리에 올라온 다른 프로세스들은 CPU가 점유 상태가 아닐 때까지 기다려야 한다.
- 이때, 자유 상태의 CPU가 어떤 기준으로 다음 프로세스를 선택할 것인가?
- CPU 스케줄링은 CPU가 다음에 수행할 프로세스의 실행 순서를 정하는 방법이다.
- 멀티프로그래밍의 목적은 CPU 이용률을 최대화하는 것이다.
CPU-I/O 버스트 사이클
-
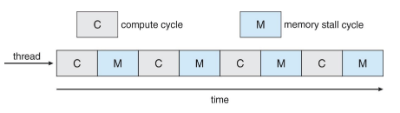
프로세스 실행은 CPU 실행과 입출력(I/O) 대기의 사이클로 구성된다.
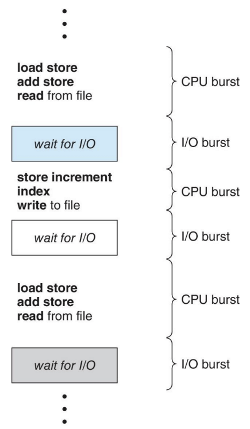
- CPU 버스트 : 프로세스의 명령어들을 수행하는 상태
- I/O 버스트 : 사용자로부터 입력받기를 기다리거나 결과를 출력하는 상태
-
프로세스들은 CPU 버스트와 I/O 버스트 상태 사이를 왔다갔다한다.
- 프로세스의 실행은 CPU 버스트로 시작한다.
- 뒤이어 I/O 버스트가 발생한다. 이후 두 상태를 계속하여 교대한다.
-
CPU 버스트의 지속시간에 따른 발생 빈도 ![[image-2.png]]
- 짧은 CPU 버스트는 아주 잦은 빈도로 발생하는 반면,
- 긴 CPU 버스트는 드물게 발생
CPU 스케줄러
-
CPU가 유휴상태가 될 때마다, 운영체제는 Ready Queue에 있는 프로세스 중에서 하나를 선택
- 선택은 Short-Term 스케줄러에 의해 수행된다.
- 메모리에 있는 Ready 상태의 프로세스 중에서 하나를 선택하여, CPU를 할당받는다.
- Ready Queue는 FIFO(선입선출)일수도, 그렇지 않을수도 있다.
선점/비선점 스케줄링 ((Non-)Preemptive Scheduling)
-
❎ 비선점(Non-Preemptive) 스케줄링
- 누군가 점유중이면 CPU를 절대 가져갈 수 없는 스케줄링
- CPU가 현재 실행중인 프로세스를 완료할때까지 다른 프로세스들을 대기(wait)시킨다.
- 오직 현재 실행중인 프로세스가 종료되거나 입/출력을 위해 대기상태로 들어가는 경우에만 다른 프로세스들이 실행될 수 있다.
-
✅ 선점(Preemptive) 스케줄링
- 먼저 빼앗는 사람이 CPU를 가져가는 스케줄링
- 현재 실행중인 프로세스가 있어도, (더 우선순위가 높다면) 스케줄러가 CPU를 넘김
- 실행중인 프로세스가 다른 프로세스에 CPU 제어권을 선점당하면, 해당 프로세스는 Running 상태에서 Ready 상태로 변한다.
- I/O 완료 등으로 Waiting → Ready 상태가 된 프로세스가 CPU를 선점할 수도 있다.
- 공유 데이터에 접근하는 데 따르는 비용이 발생한다.
-
CPU 스케줄링 결정은 아래 네 가지 상황 아래에서 발생한다.
- 프로세스가 Running → Waiting 상태로 전환될 때 (예: I/O 요청)
- 프로세스가 Running → Ready 상태로 전환될 때 (예: 인터럽트 발생)
- 프로세스가 Waiting → Ready 상태로 전환될 때 (예: I/O 완료)
- 프로세스가 종료(Terminate)될 때
-
상황 1), 4) 에서만 스케줄링이 발생할 경우
- 비선점 스케줄링이 이루어진다.
- CPU를 점유한 프로세스를 내쫓을 수 없으므로, 프로세스가 내려올 때에만 실행 가능
- 협력적(Cooperative) 스케줄링이라고도 한다.
- 실행 중인 프로세스가 자발적으로 CPU를 반납할 때만 문맥 전환이 발생한다.
-
상황 2), 3) 에서도 스케줄링이 발생할 경우
- 선점 스케줄링이 이루어질 수 있다.
- 우선순위에 따라 다른 프로세스가 CPU를 빼앗을 수 있음
- 선점 스케줄링을 위한 하드웨어(=타이머)가 필요하다.
디스패처(Dispatcher)
- CPU 스케줄링에 포함된 또 하나의 요소
- 디스패처는 Short-Term 스케줄러가 선택한 프로세스에게 CPU 제어권을 실제로 넘기는 역할을 담당한다.
-
디스패처는 다음의 작업을 포함한다.
- 문맥 교환 작업
- 사용자 모드로의 전환
- 프로그램을 다시 시작하기 위해 Application의 적절한 위치로 이동(Jump)하는 일
-
🚸 디스패치 지연 (Dispatch Latency)
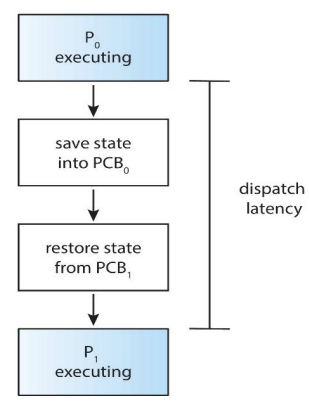
- 디스패처가 하나의 프로세스를 정지한 후, 다른 프로세스의 수행을 시작하는 데까지 소요되는 시간
- 즉, 오버헤드(Overhead)에 해당한다.
5.2 스케줄링 기준
- 여러 CPU 스케줄링 알고리즘들은 서로 다른 특성을 가지고 있다.
- 특정 상황에 맞는 알고리즘을 선택하기 위해, 알고리즘을 고르는 기준(Criteria)에 대해 고려해야 한다.
-
CPU Utilization (CPU 이용률)
- CPU가 얼마나 바쁘게 유지되는지의 정도를 가리킴. 실제 40~90% 정도의 범위를 가진다.
-
Throughput (처리량)
- 단위 시간 당 완료된 프로세스의 개수. 프로세스의 길이에 따라 처리량은 달라진다.
-
Turnaround Time (총처리시간)
- 메모리에 들어가기 까지의 시간 + Ready Queue 대기 시간 + CPU 처리 시간 +입출력 시간의 총합 (완료 시간 ↔ 도착 시간)
-
Waiting Time (대기시간)
- Ready Queue 대기 시간의 합
-
Response Time (응답시간)
- 요청 이후 응답까지 걸린 시간
- 프로세스가 Ready 상태로 진입한 이후 처음으로 CPU를 할당받아 실행 시작까지 걸린 시간
-
스케줄링 알고리즘의 목표
- CPU 이용률(CPU Utilization)과 처리량(Throughput)을 최대화하고,
- 총처리시간(Turnaround Time), 대기시간(Waiting Time), 응답시간(Response Time)을 최소화하는 것
- 평균보다는 최소값과 최대값을 최적화하는 것이 중요하다.
- (상호작용 시스템의 경우) 응답 시간의 분산을 최소화하는 것이 중요하다.
5.3 스케줄링 알고리즘
1️⃣ FCFS (First-Come, First-Served) 스케줄링
-
선입-선처리 스케줄링이라고도 불린다.
- 비선점 스케줄링의 한 종류이다. ( = 한 번 CPU에 올라간 프로세스는 끌어내릴 수 없음)
- 먼저 요청하는 프로세스가 CPU를 먼저 할당받는 가장 간단한 방식의 스케줄링
-
FCFS 스케줄링의 장점
- 작성하기 쉽고, 이해하기 쉽다.
-
FCFS 스케줄링의 단점
- 호위 효과 (Convoy Effect)
- 수행시간이 짧은 프로세스는 긴 프로세스가 끝날 때까지 대기하는 것
-
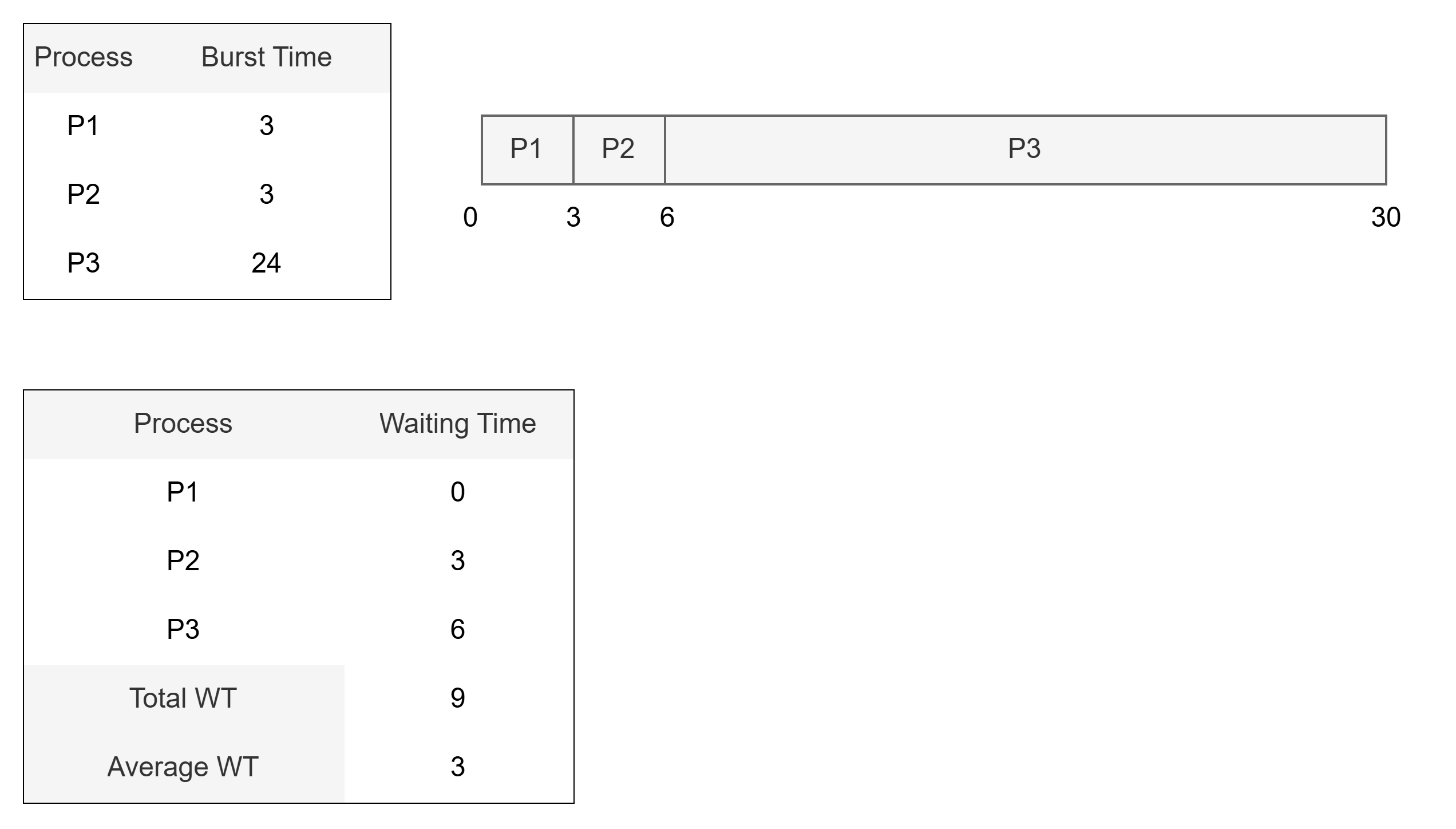
예시 1
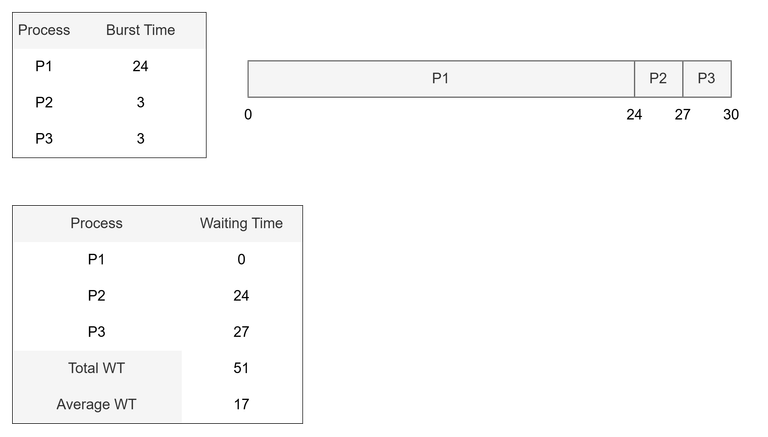
- 수행시간이 긴 프로세스가 먼저 요청하고, 수행시간이 짧은 프로세스가 이후 실행
- 대기 시간을 합하여 나눈 값 (평균 대기시간) = 51 / 3 = 17

- 평균 총처리시간 = ( 24 + 27 + 30 ) / 3 = 27
- 총처리시간은 대기시간도 포함하므로, 대기시간이 길어져 총처리시간도 높게 측정
-
예시 2
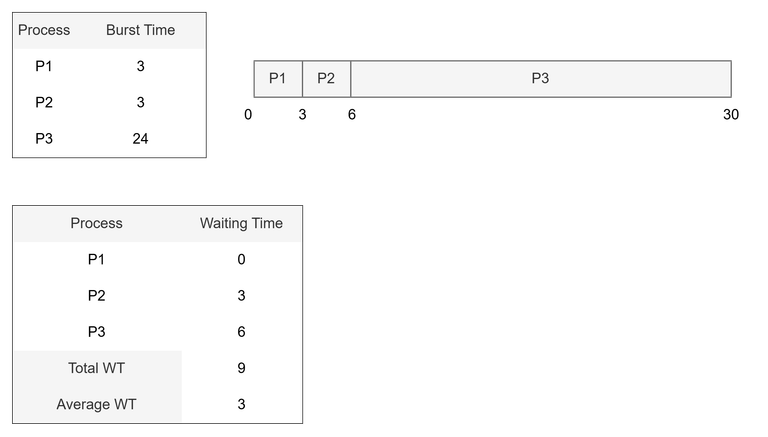
- 수행시간이 짧은 P2, P3가 먼저 요청 → P1이 나중에 요청
- 평균 대기시간 = 9 / 3 = 3

- 평균 총처리시간 = (3 + 6 + 30 ) / 3 = 13
- 평균 대기시간이 짧아진 만큼, 총처리 시간도 짧아짐
- FCFS는 프로세스가 도착한 순서에 따라 호위 효과로 인한 비효율이 발생할 수 있음



2️⃣ SJF (Shortest-Job First) 스케줄링
- 최단작업 우선 스케줄링이라고도 불린다.
-
CPU가 이용 가능해지면, 가장 작은 CPU 버스트를 가진 프로세스에게 CPU를 할당
- (이름과 다르게) 프로세스의 길이가 아닌, CPU 버스트의 크기가 기준임
- FCFS 스케줄링의 문제점을 개선하기 위해 나온 알고리즘
- CPU 버스트의 크기가 동일하다면 ‘FCFS 스케줄링’을 적용한다. (=선입 선처리)
-
SJF 알고리즘의 어려움
- SJF 알고리즘은 CPU 스케줄링 중 가장 최적(Optimize)하다.
- 그러나, CPU 버스트의 길이를 알 수 있는 방법이 없다.
-
이를 해결하기 위해 과거 기록을 바탕으로 예측해야 한다.
- 또는 사용자 지정 값을 설정한다.
-
다음 CPU 버스트의 길이 추정
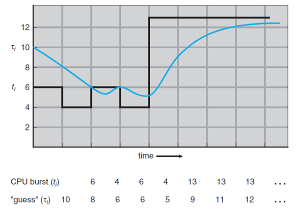
- 다음 CPU 버스트 길이를 예측하기 위해 지수평균을 사용한다.
-
- : 실제 i번째 CPU 버스트 시간
- : 이전에 예측했던 CPU 버스트 시간
-
: 가중치 (최근 측정 값을 얼마나 신뢰할 것인가?)
- 예시에서는 1/2 (=0.5) 로 계산
- 처음 = 10 으로 시작하여, 1초 후, 측정
- 다음 예측 길이는 8 (0.5 * 6 + 0.5 * 10 = 8)
-
🅰️ 선점형 SJF 스케줄링 vs. 🅱️ 비선점형 SJF 스케줄링
- SJF 스케줄링은 선점형이거나 또는 비선점형일 수 있다.
-
앞의 프로세스가 실행되는 동안 더 짧은 CPU 버스트를 가진 프로세스 발견 시
- 선점형 : 현재 실행하는 프로세스로부터 CPU 제어권을 선점함
- 비선점형 : 현재 실행하는 프로세스가 마칠 때까지 CPU 제어권을 가질 수 없음
-
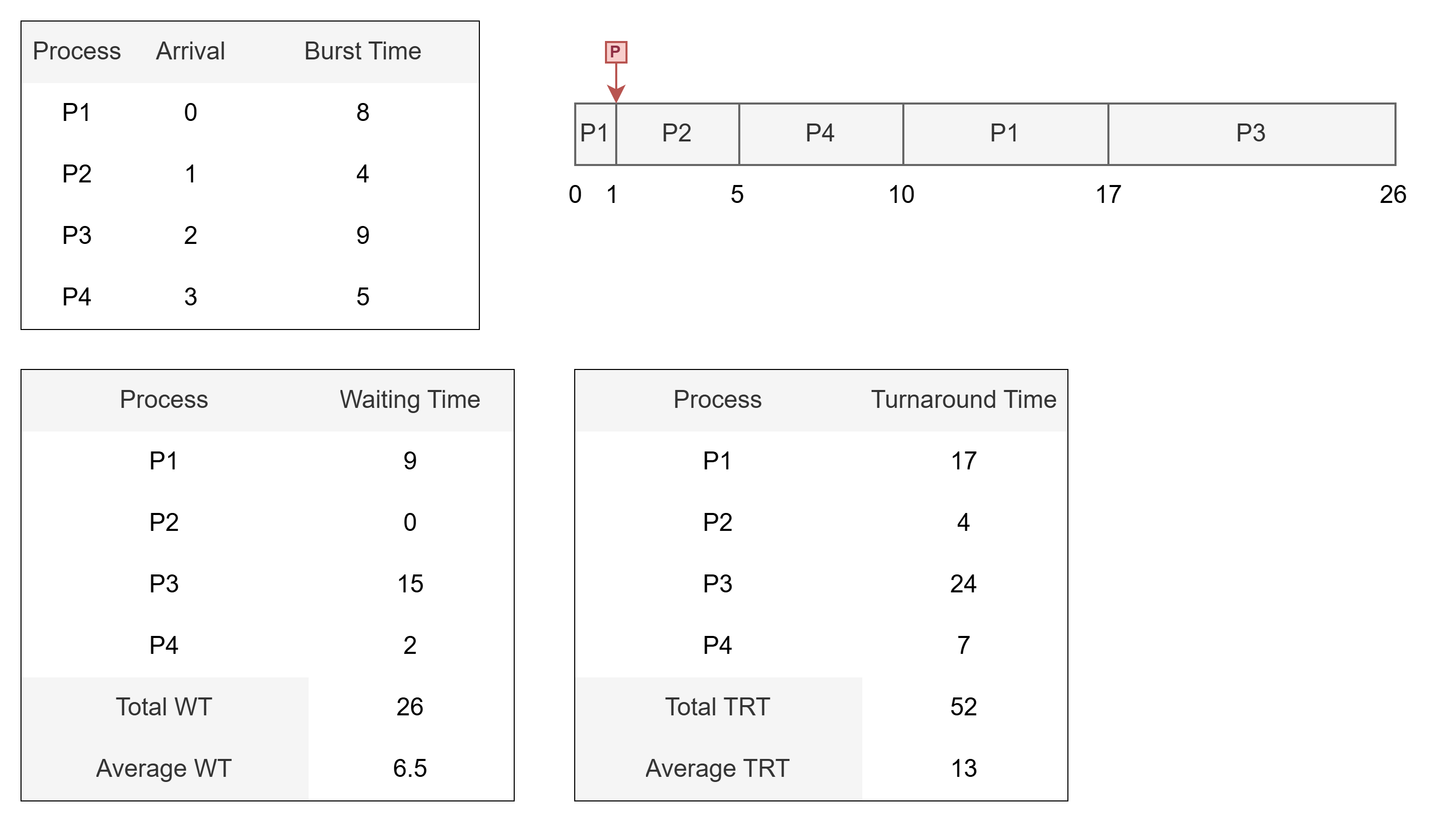
🅰️ 선점형 SJF 스케줄링 예시
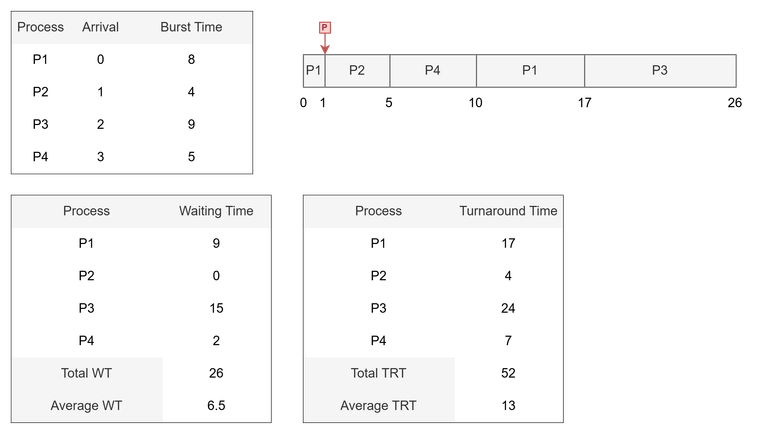
- P1이 먼저 도착했음에도, 버스트 시간이 짧은 P2가 도착시점 이후 CPU를 선점한다.
- 이어서 P4의 CPU 버스트 크기가 작으므로 P1보다 앞서 실행된다.
-
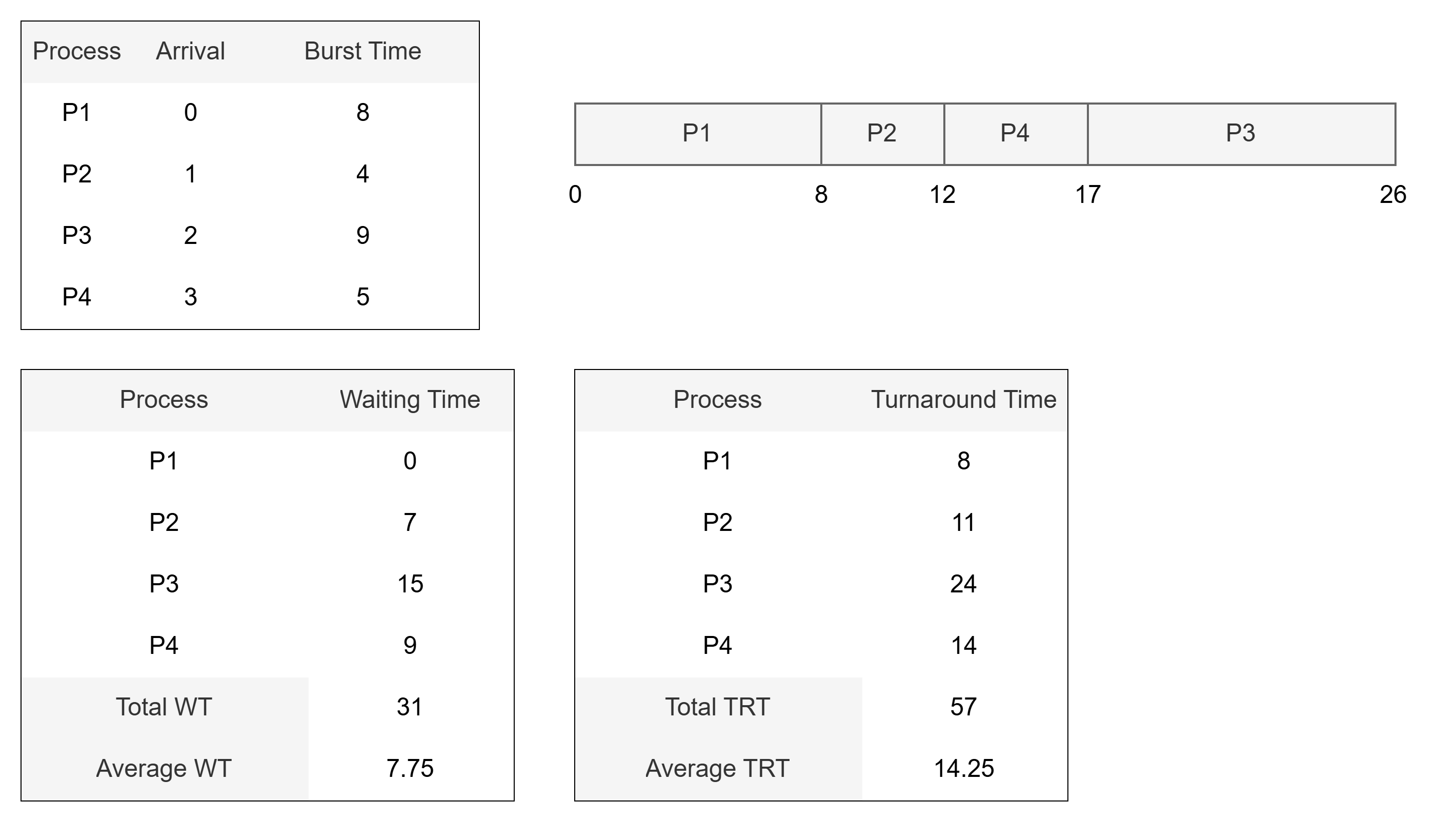
🅱️ 비선점형 SJF 스케줄링 예시
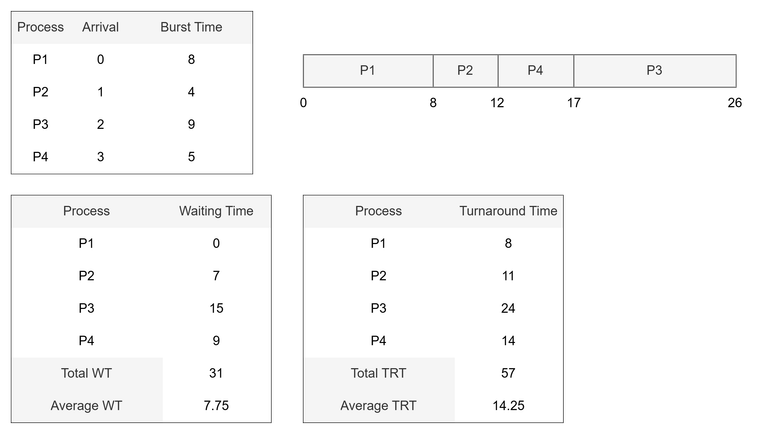
- CPU를 점유 중인 프로세스는 실행을 대기/종료 전환하기까지 프로세스를 계속한다.
- 해당 예시에서, 비선점형 SJF가 선점형 SJF보다 조금 더 느리며 비효율적이다.
- 그러나 경우에 따라 비선점형 스케줄링이 더 유리한 경우도 가능하다.
3️⃣ 우선순위 (Priority) 스케줄링
- 앞서 확인한 SJF 알고리즘은 우선순위 알고리즘의 특수한 경우에 해당한다.
-
우선순위 스케줄링은 각각의 프로세스가 가진 우선순위를 비교해, 가장 높은 우선순위를 가진 프로세스에게 CPU 제어권을 할당하는 알고리즘이다.
- 우선순위는 0~n 까지의 일정 범위의 수가 사용되며, 교재에서는 0을 최우선 프로세스로 간주한다.
- 우선순위가 같은 프로세스는 FCFS 알고리즘(=선입 선처리)으로 처리한다.
-
우선순위는 내부적/외부적 요인으로 결정될 수 있다.
- 내부적 요인에 해당 : 시간 제한, 메모리 요구 비율, 열린 파일의 수, I/O 버스트 등
- 외부적 요인에 해당 : 프로세스의 중요성, 비용 등
-
예시 (비선점형 우선순위 스케줄링)
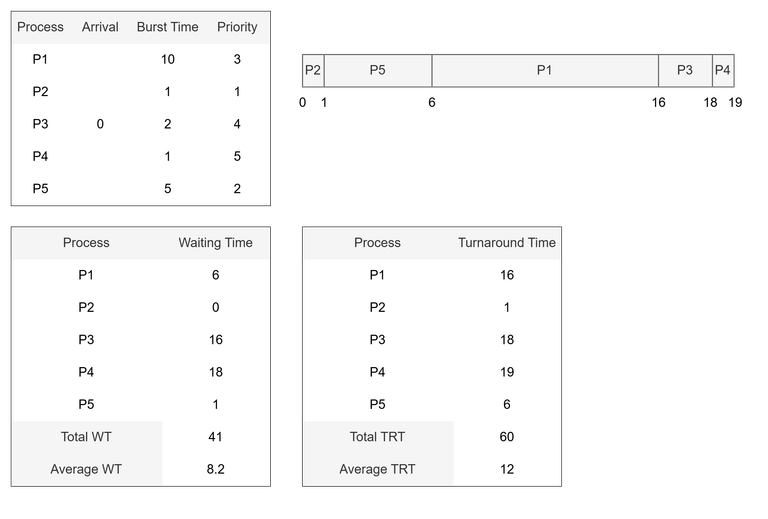
-
🅰️ 선점형 우선순위 스케줄링 vs. 🅱️ 비선점형 우선순위 스케줄링
- 우선순위 스케줄링은 선점형이거나 또는 비선점형일 수 있다.
-
앞의 프로세스가 실행되는 동안 더 우선적인 프로세스가 Ready Queue에 도착 시
- 선점형 : 현재 실행하는 프로세스로부터 CPU 제어권을 선점함
- 비선점형 : 현재 실행하는 프로세스가 마칠 때까지 CPU 제어권을 가질 수 없음
-
😭 무한 봉쇄 / 굶음 문제 (indefinite blocking / starvation)
- 실행 준비 상태에 있으나 이론적으로 무한히 CPU 제어권을 얻지 못할 수 있음
- 해결 방법으로 Aging 기법이 사용됨 (=노화)
- 일정 주기마다 프로세스 우선순위를 1씩 증가시킨다.
- 시간이 지나서 우선순위가 가장 낮았던 프로세스도 최우선이 되어 실행에 도달할 수 있다.
-
라운드 로빈을 적용한 우선순위 스케줄링
- 우선순위가 높은 프로세스가 CPU 제어권을 얻음 (선점형 우선순위 스케줄링)
- 같은 우선순위끼리는 시간 할당량(Time Quantum)만큼 순서대로 실행
- 시간 할당량이 2인 RR+Priority Algorithm 예시
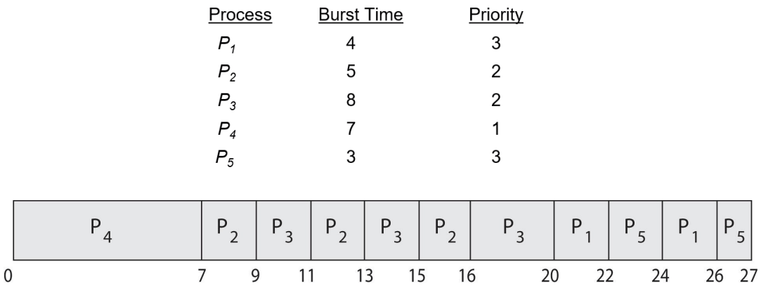
- RR은 단순히 Ready Queue에 도착한 순서대로 시간 할당량을 부여하는 방식
- RR+Priority Algorithm 은 중요한 작업을 더 빨리 처리하면서도 공정성을 유지할 수 있다.
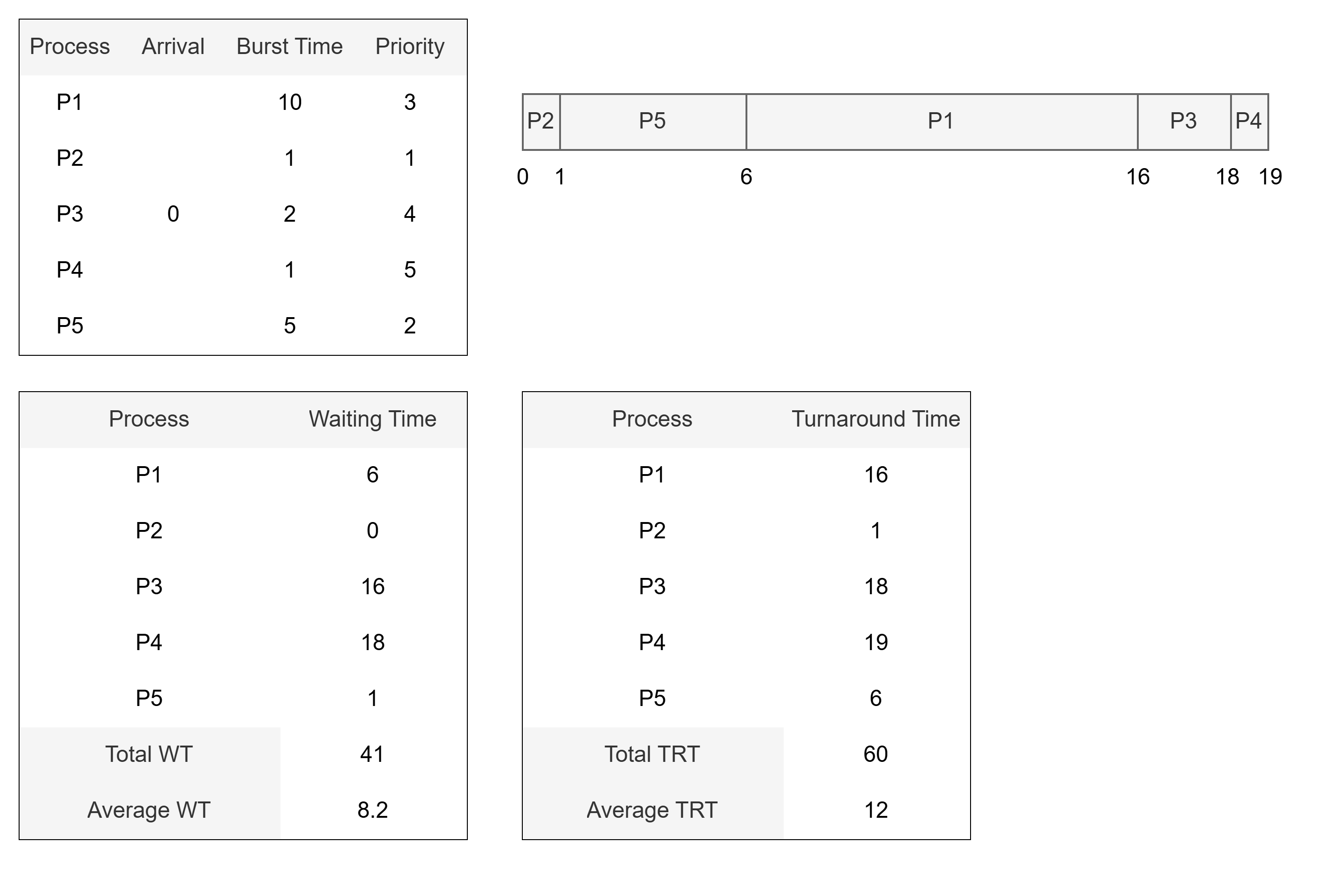
4️⃣ 라운드 로빈 (Round-Robin, RR) 스케줄링
- FCFS 알고리즘과 유사한 방식이지만, 선점이 추가된 스케줄링 알고리즘에 해당한다.
-
시간 할당량(Time Quantum)을 정의하여 한 번에 한 프로세스에게 일정 시간만큼 CPU를 할당한다.
- 시간 할당량은 일반적으로 약 10~100ms에 해당한다.
-
Ready Queue는 Circular Queue(원형 큐)처럼 동작
- CPU 버스트 길이가 시간할당량보다 짧은 경우: 프로세스 스스로 CPU 제어권을 반납하여 종료 또는 대기 상태로 전이됨. 스케줄러는 다음 프로세스로 진행
- CPU 버스트 길이가 시간할당량보다 긴 경우: 타이머가 끝나면 인터럽트 발생, 문맥 교환 수행. 실행하던 프로세스는 Ready Queue의 꼬리에 넣음
-
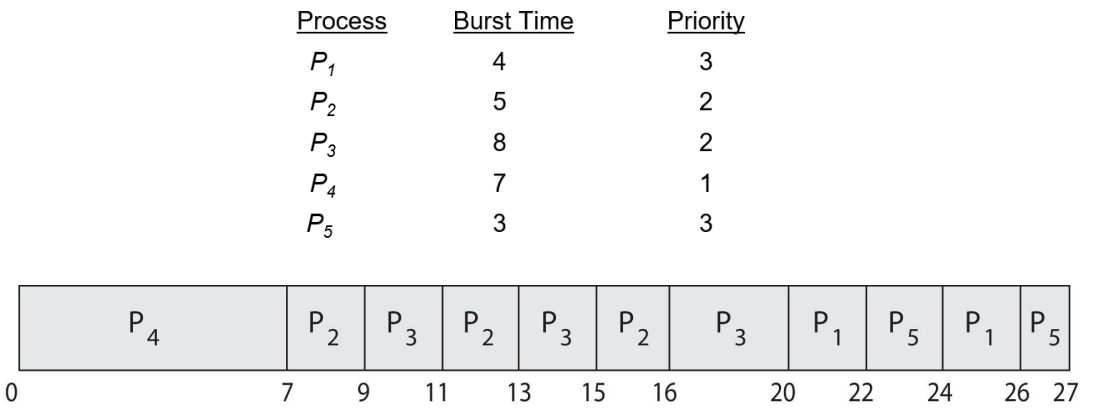
예시

-
평균 총처리시간: 시간 할당량의 크기에 좌우된다
- 일반적으로 단일 시간할당량 안에 CPU 버스트를 끝낸다면, 평균 총처리시간은 개선된다.
- 더 잘게 나눌 때 문맥교환 시간이 추가되므로, 평균 총처리 시간은 증가하게 된다.
- 그러나, 시간할당량이 너무 크면 FCFS 정책으로 퇴보하므로, 적절한 Slicing이 필요하다. (→ A rule of thumb)
-
-
RR 스케줄링의 특징
- RR 스케줄링은 모든 프로세스가 CPU를 공평하게 사용할 수 있게 한다.
- RR 알고리즘의 평균 대기 시간은 종종 길어질 수 있다.
-
RR 스케줄링의 성능은 시간할당량의 크기에 매우 많은 영향을 받는다.
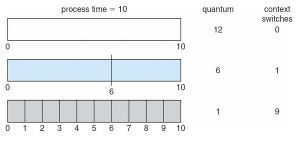
- 시간할당량이 아주 큰 경우: FCFS와 동일하게 동작
- 시간할당량이 작은 경우: 프로세스 공유 (1/n 속도로 실행하는 효과)
- 시간할당량이 지나치게 작은 경우: 문맥 교환(Context Switching) 시간이 오히려 많아져 전체 시스템 성능을 저하시킬 수 있음
-
시간할당량은 문맥 전환 시간에 비해 커야 한다.
- 문맥 교환 시간이 시간할당량의 10%에 근접한다면, CPU 시간의 10%는 실상 문맥 전환에만 사용되는 셈이다
-
A rule of thumb (경험의 법칙)
- 모든 CPU 버스트 중 80%는 시간 할당량보다 작아야 한다. (가장 적절한 시간할당량)
5️⃣ 다단계 큐 (Multilevel Queue) 스케줄링
-
Ready Queue를 여러 개의 별도의 큐로 분류하여 수행하는 방식
- 유형(포그라운드, 백그라운드) 또는 메모리 크기, 우선순위 등 기준에 따라 프로세스를 구분한다.
-
각각의 큐는 자신만의 스케줄링 알고리즘을 가진다.
- 예를 들어, 포그라운드 큐는 RR 알고리즘을, 백그라운드 큐는 FCFS 알고리즘을 적용할 수 있다.
-
다단계 큐 스케줄링은 반드시 큐 사이의 스케줄링도 필요로 한다.
-
일반적으로 고정된 선점형 우선순위 스케줄링을 사용한다.
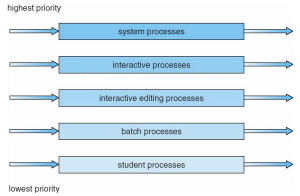
- 예시와 같이, 가장 중요한 시스템 프로세스를 최우선으로, 기타 프로세스를 차우선으로 스케줄링할 수 있다.
-
각 큐는 낮은 우선순위의 큐보다 절대적인 우선순위를 가진다.
- 더 우선순위의 큐가 비어 있지 않으면, 낮은 순위 큐에 있는 프로세스는 실행되지 않는다.
-
또는, 큐들 사이에 시간을 나누어 사용할 수 있다.
- CPU 시간의 n% … n% 씩을 각각 할당하는 방식
-
6️⃣ 다단계 피드백 큐 스케줄링
-
다단계 큐 스케줄링은 일반적으로 프로세스들이 시스템 진입 시에 영구적으로 하나의 큐에 할당된다.
- 예를 들어, 포그라운드와 백그라운드 프로세스를 위해 별도의 큐가 분리된 경우,
- 백그라운드 프로세스는 포그라운드 프로세스가 될 수 없으며, 큐 간 이동할 수 없다
- 해당 방식은 적은 스케줄링 오버헤드를 가지는 것이 장점이지만, 융통성이 적다.
-
다단계 피드백 큐 스케줄링 알고리즘 특징
- 프로세스가 큐 사이를 이동하는 것을 허용한다.
-
프로세스를 CPU 버스트 성격에 따라 구분한다.
- 어떤 프로세스가 CPU 시간을 너무 많이 사용하면, 낮은 우선순위 큐로 이동시킨다.
- I/O 중심의 프로세스와 대화형 프로세스는 높은 우선순위의 큐에 넣는다.
- 낮은 우선순위 큐에서 너무 오래 대기하는 프로세스는 높은 우선순위 큐로 이동할 수 있다. (= Aging 노화)
- 이러한 노화 형태는 굶음(starvation) 상태를 예방할 수 있다.
-
예시
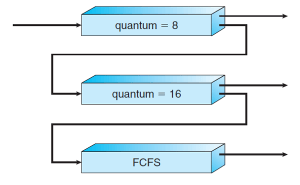
-
번호가 0 - 2 까지인 세 개의 큐를 가진 다단계 피드백 큐 스케줄러를 가정
- 큐 0의 모든 프로세스를 실행하며, 큐 0이 비어있을 때만 큐 1에 있는 프로세스를 실행한다.
- 큐 1의 모든 프로세스를 실행하며, 큐 1이 비어있을 때만 큐 2에 있는 프로세스를 실행한다.
-
Ready Queue로 들어오는 프로세스는 큐 0번에 넣어진다.
- 큐 0번에 있는 프로세스에게는 8밀리초의 시간 할당량이 주어진다.
- 이 시간 내에 끝내지 못한 프로세스는 큐 1번의 꼬리로 이동한다.
-
큐 1번에 들어오는 프로세스는 16밀리초의 시간 할당량이 주어진다.
- 이 시간 내에 끝내지 못한 프로세스는 큐 2번의 꼬리로 이동한다.
- 큐 1번에 들어오는 프로세스는 FCFS의 알고리즘으로 선입 선처리한다.
-
-
다단계 피드백 큐 스케줄링의 장점
- CPU 버스트가 짧은 프로세스들은 8밀리초를 할당받은 큐에서 완료되어 서비스를 빨리 받게 된다.
- 반대로 긴 프로세스들은 계속 차순위 큐로 가게 되어 마지막에는 FCFS 방식으로 수행하게 될 것이다.
- 즉, 수행시간이 긴 프로세스일수록 뒤의 큐로 넣어지게 되는 방식에 해당한다.
5.4 스레드 스케줄링
-
다대일(N:1) 또는 다대다(N:M) 모델에서는 스레드 라이브러리가 유저 스레드를 LWP에 매핑하여 실행한다.
- 이를 보통 프로세스 경쟁 범위(PCS, Process-Contention Scope) 라고 한다.
- 동일한 프로세스 내의 스레드 간 경쟁을 의미한다.
- 일반적으로 프로그래머가 설정한 우선순위를 통해 결정한다.
-
운영체제에서 스케줄링하는 대상 스레드는 커널 스레드이다.
- 사용자 스레드는 스레드 라이브러리에 의해 관리되며, 운영체제는 사용자 스레드의 존재를 알지 못한다.
- 이를 시스템 경쟁 범위(SCS, System-Contention Scope)이라고 하며, 시스템 전체 스레드 간 경쟁을 의미한다.
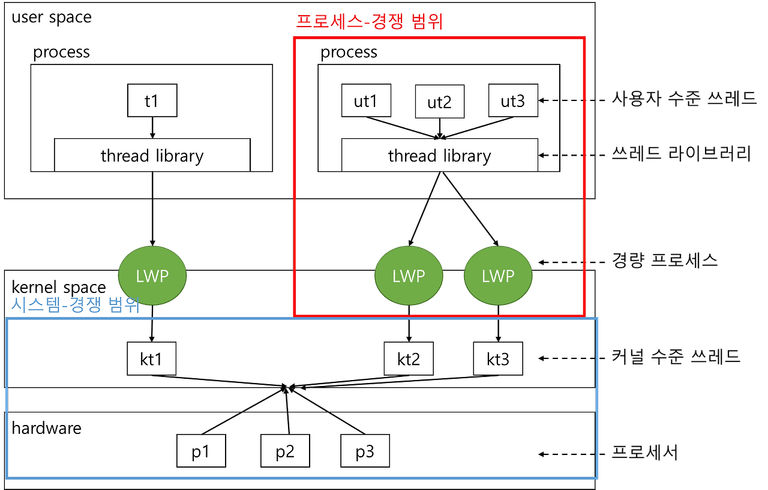
5.5 멀티프로세서 스케줄링
- 여러 개의 CPU가 존재할 경우, CPU 스케줄링은 더 복잡해진다.
-
멀티프로세서는 다음과 같은 아키텍처 중 하나일 수 있다:
- 멀티코어 CPU (Multicore CPUs)
- 멀티스레드 코어 (Multithreaded Cores)
- NUMA 시스템 (Non-Uniform Memory Access systems)
- 이기종 멀티프로세싱 (Heterogeneous Multiprocessing)
멀티프로세서 스케줄링 접근 방법
-
멀티프로세서 시스템의 CPU 스케줄링 방법에는 두 가지가 존재한다.
- 비대칭 멀티프로세싱 (asymmetric multiprocessing)
- 대칭 멀티프로세싱 (symmetric multiprocessing, SMP)
-
비대칭형 멀티프로세싱 (Asymmetric Multiprocessing)
- 하나의 프로세서(메인 서버)가 모든 스케줄링 결과 입/출력 처리 그리고 다른 시스템으로의 이동을 취급하도록 한다.
- 다른 처리기들은 Application Code(사용자 코드)만을 수행한다.
- 자료 공유의 필요성을 배제하기 때문에 간단하다는 특징이 있다.
-
대칭형 멀티프로세싱 또는 SMP (Symmetric Multiprocessing)
- 각각의 프로세서가 독자적으로 스케줄링하는 방법
-
각 프로세서의 스케줄러가 Ready Queue를 검사해서 실행할 프로세스를 선택하여 수행한다.
- 이때, Ready Queue는 공동운영 / 각자운영 둘 다 가능하다.
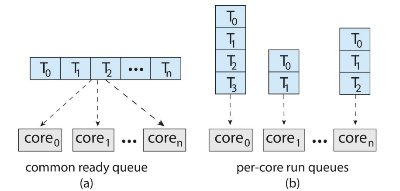
- 단, 공동 자료 구조 접근 시 신중하게 처리해야 한다.
- 두 프로세서가 같은 프로세스를 선택하지 않도록 해야하며, 프로세스들이 큐에서 사리지지 않도록 보장해야 한다.
- 이때, Ready Queue는 공동운영 / 각자운영 둘 다 가능하다.
프로세서 친화성 (Processor Affinity)
-
한 스레드(또는 프로세스)가 이전에 실행되었던 CPU에서 계속 실행되기를 선호하는 성질
- 두 개의 프로세서에서 하나의 프로세스가 실행된다면, 한 프로세스에서는 의미 없는 캐시 메모리 내용을 무효화해야 하고, 다른 프로세서에는 캐시 메모리가 다시 채워져야 한다.
- 캐시를 무효화하고 다시 채우는 작업은 비용이 많이 들기 때문에, 한 프로세서에서만 같은 프로세스를 실행하는 것이 효율적이다.
- 프로세서 친화성을 통해 캐시 적중률(Cache Hit-rate)을 높여 성능 향상을 기대할 수 있다.
- 부하 분산(load balancing) 과정에서 스레드가 다른 프로세서로 이동될 수 있는데, 이 경우 이전 프로세서의 캐시에 저장된 정보를 잃게 되어 성능 저하가 발생할 수 있다.
-
프로세서 친화성의 종류
-
약한 친화성(Soft affinity)
- 운영체제가 동일한 처리기에서 프로세스를 실행시키려고 노력하는 정책을 가지고 있지만 보장하지는 않을 때, 이 경우 프로세스가 처리기 사이에서 이주하는 것이 가능함
-
강한 친화성(Hard affinity)
- 시스템 콜을 통하여 프로세스는 다른 처리기로 이주하지 않겠다고 명시적으로 지정할 수 있음
-
로드 밸런싱 (Load Balancing)
- SMP 시스템의 모든 처리기 사이에 부하가 고르게 배분되도록 시도하는 것
-
로드밸런싱의 두 가지 방법
-
Push 이주(Push Migration)
- 특정 태스크가 주기적으로 각 처리기의 부하를 검사/확인한다.
- 만일 불균형 상태로 밝혀지면 과부하인 처리기에서 쉬고 있거나 덜 바쁜 처리기로 프로세스를 이동(또는 push)시킴으로써 부하를 분배하는 방식
-
Pull 이주(Pull Migration)
- 쉬고 있는 프로세서가 바쁜 처리기를 기다리고 있는 프로세스를 가져오는 방식
-
멀티코어 프로세서
-
최근 추세는 여러 개의 프로세서 코어를 하나의 물리적인 칩에 배치하는 것
- 더 빠르며 ****전력 소모도 적다.
멀티스레드 멀티코어 시스템
- Multithreaded Multicore System
-
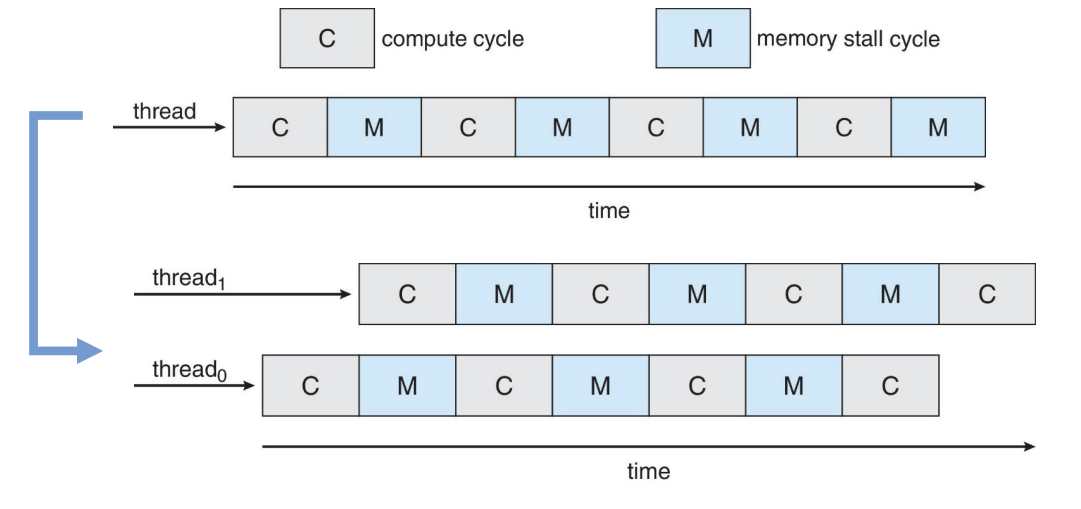
한 코어당 여러 개의 스레드를 실행하는 구조도 증가하고 있다. (=멀티스레드 멀티코어)
- 메모리 지연이 발생하는 동안, 다른 스레드의 작업을 진행함으로써 성능을 향상시킴
-
메모리 지연 (memory stall)
- 캐시 미스(Cache Miss) 등 여러 원인으로 메모리가 중단되는 것
-
각 코어는 1개 이상의 하드웨어 스레드를 가진다.
- 한 스레드에서 메모리 지연(memory stall) 이 발생하면, 다른 스레드로 전환하여 작업을 계속 수행할 수 있다.
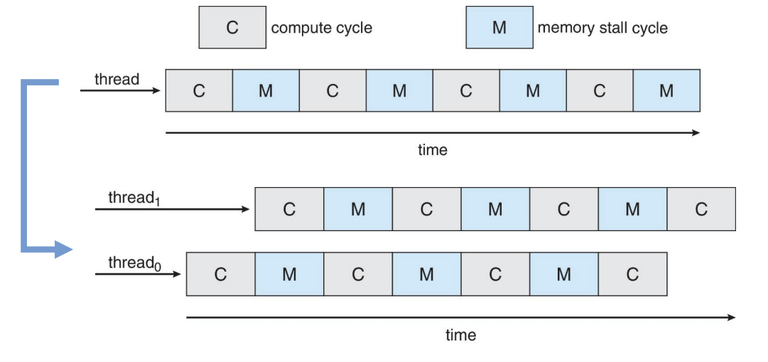
- 한 스레드에서 메모리 지연(memory stall) 이 발생하면, 다른 스레드로 전환하여 작업을 계속 수행할 수 있다.
-
칩 멀티스레딩(Chip-Multithreading, CMT) 은 각 코어에 여러 하드웨어 스레드를 할당하는 방식이다.
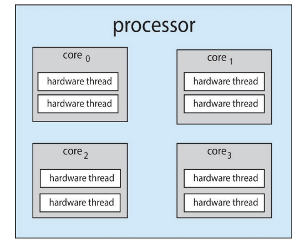
- 인텔(Intel)에서는 이를 하이퍼스레딩(Hyperthreading) 이라고 부른다.
-
예: 쿼드코어 시스템에서 코어당 2개의 하드웨어 스레드를 가진 경우,
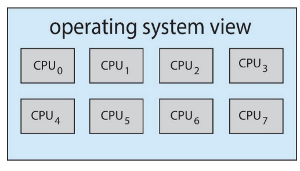
- 운영체제는 총 8개의 논리 프로세서(logical processors) 를 인식하게 된다.
-
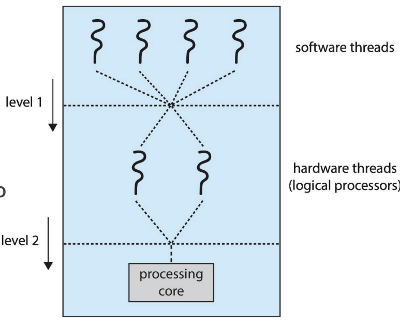
멀티스레드 멀티코어 시스템에는 두 단계의 스케줄링이 존재한다.
-
운영체제 수준 스케줄링
- 어떤 소프트웨어 스레드를 논리 CPU에서 실행할지 결정
-
코어 내부의 하드웨어 스케줄링
- 하나의 물리 코어에서 어떤 하드웨어 스레드를 실행할지 결정
-
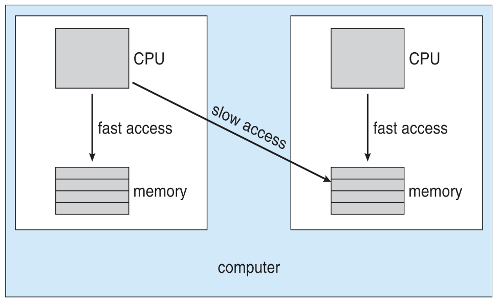
NUMA와 CPU 스케줄링
- 운영체제가 NUMA(Non-Uniform Memory Access)를 인식하는 경우, 스레드가 실행 중인 CPU에 가까운 메모리를 할당하려고 한다.
5.6 실시간 CPU 스케줄링
- 실시간 시스템에서는 명확한 도전 과제들이 존재한다.
-
실시간 시스템의 두 종류
-
약한 실시간 시스템 (Soft Real-Time Systems)
- 중요한 실시간 프로세스가 언제 스케줄링될지 보장되지 않는다.
-
강한 실시간 시스템 (Hard Real-Time Systems)
- 작업은 반드시 데드라인(deadline) 내에 처리되어야 한다.
-
지연시간 최소화(Minimizing Latency)
-
실시간 성능에 영향을 주는 두 가지 주요 지연(latency)
- 인터럽트 지연 시간
- 디스패치 지연 시간
-
인터럽트 지연 시간 (Interrupt Latency)
- 인터럽트가 발생한 시점부터 해당 인터럽트를 처리하는 루틴이 시작되기까지의 시간
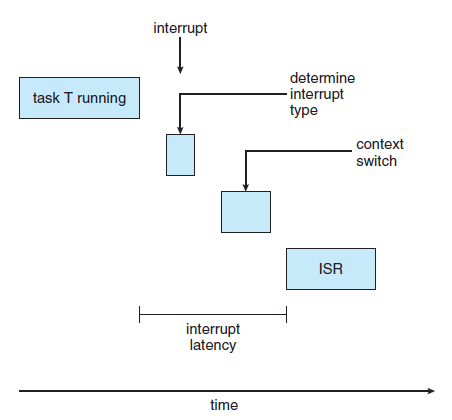
- 인터럽트가 발생한 시점부터 해당 인터럽트를 처리하는 루틴이 시작되기까지의 시간
-
디스패치 지연 시간 (Dispatch Latency)
- 현재 프로세스를 CPU에서 제거하고, 다른 프로세스로 전환(switch) 하는 데 걸리는 시간
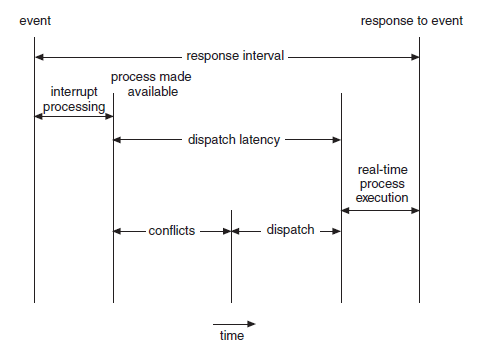
-
디스패치 지연 시간(dispatch latency)의 충돌 단계(conflict phase) 에 포함되는 주요 상황
-
커널 모드에서 실행 중인 프로세스의 선점(preemption)
- 커널 모드에서 실행 중인 프로세스를 중단시키는 데 시간이 걸릴 수 있음
-
저우선순위 프로세스가 고우선순위 프로세스가 필요한 자원을 점유하고 있는 경우
- 고우선순위 프로세스가 실행되기 위해 저우선순위 프로세스가 해당 자원을 해제(release) 해야 하는 상황
-
- 현재 프로세스를 CPU에서 제거하고, 다른 프로세스로 전환(switch) 하는 데 걸리는 시간
1️⃣ 우선순위 기반 스케줄링(Priority-Based Scheduling)
-
실시간 스케줄링을 위해서는 스케줄러가 선점형(preemptive), 우선순위 기반(priority-based) 스케줄링을 지원해야 한다.
- 단, 이는 약한 실시간(soft real-time) 만 보장할 수 있다.
- 강한 실시간(hard real-time) 을 위해서는, 작업이 정해진 기한(deadline) 을 충족할 수 있어야 한다.
-
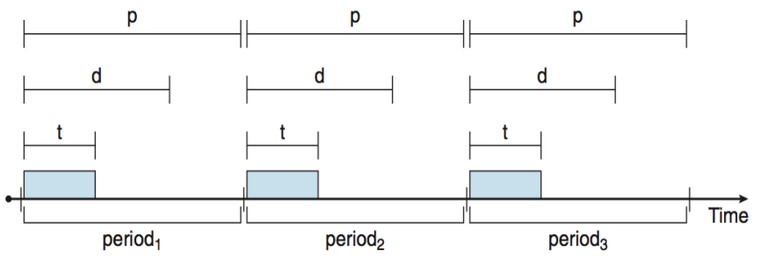
실시간 프로세스는 새로운 특성을 가진다: 특히 주기적인 작업(periodic task) 은 일정한 간격으로 CPU를 요구한다.
-
하나의 주기적 작업은 다음과 같은 속성을 가진다:
- 처리 시간(t), 기한(deadline, d), 주기(period, p)
- 수학적 관계:
0 ≤ t ≤ d ≤ p - 주기적 작업의 실행 비율(rate) 은
1/p
-
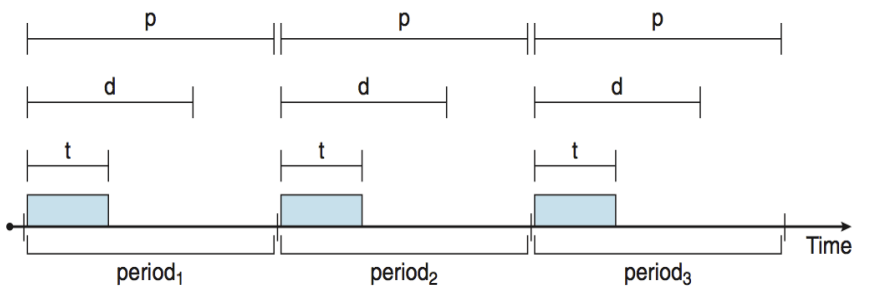
2️⃣ Rate-Monotonic 스케줄링
- 비율 단조 스케줄링
- 우선순위는 작업의 주기의 역수(inverse of its period)를 기준으로 할당된다.
- 짧은 주기(period) 를 가진 작업은 더 높은 우선순위를 가진다.
- 긴 주기를 가진 작업은 더 낮은 우선순위를 가진다.
-
예: P1은 P2보다 더 높은 우선순위를 할당받는다.


| 프로세스 | 주기 (Period) | 처리 시간 (Processing Time) | 마감 기한 (Deadline) |
|---|---|---|---|
| P1 | 50 | 20 | 다음 주기가 시작되기 전까지 CPU 버스트를 완료해야 함 |
| P2 | 100 | 35 | 다음 주기가 시작되기 전까지 CPU 버스트를 완료해야 함 |
-
Rate-Monotonic 스케줄링에서의 기한 초과(Missed Deadline)
- 비율 단조 스케줄링에서는 주기가 짧은 작업에 높은 우선순위를 부여하기 때문에, 때때로 긴 주기를 가진 작업이 기한을 초과할 수 있다.
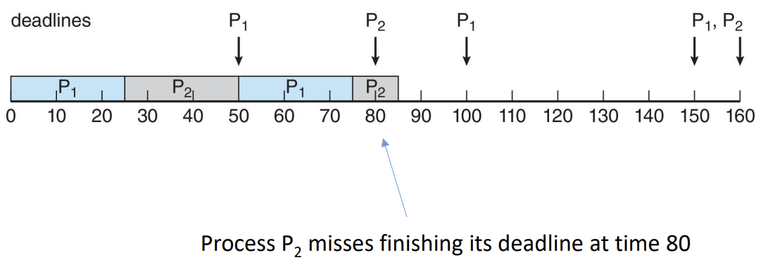
프로세스 주기 (Period) 처리 시간 (Processing Time) 마감 기한 (Deadline) P1 50 25 다음 주기가 시작되기 전까지 CPU 버스트를 완료해야 함 P2 80 35 다음 주기가 시작되기 전까지 CPU 버스트를 완료해야 함
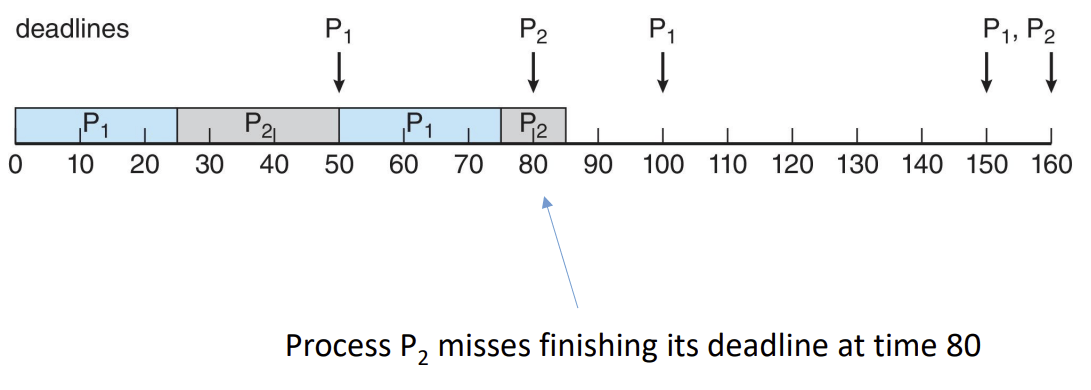
3️⃣ EDF (Earliest-Deadline-First) 스케줄링
-
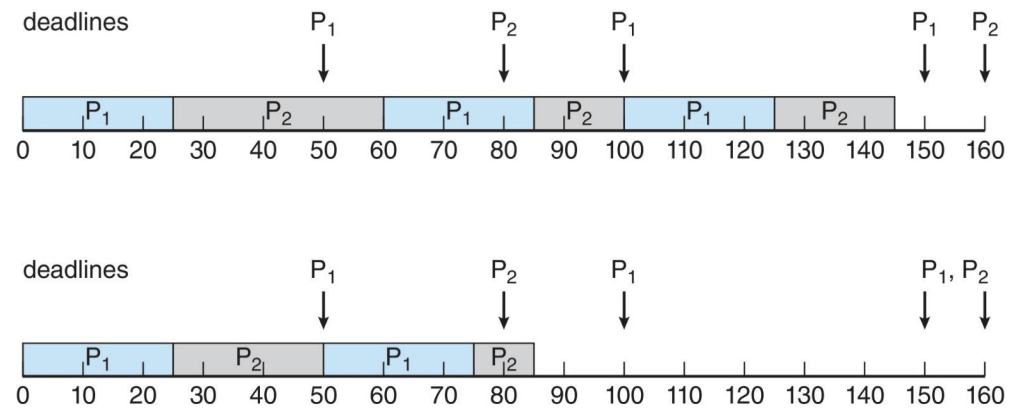
우선순위는 기한(deadline) 에 따라 할당된다.
- 기한이 빠를수록 더 높은 우선순위를 부여받는다.
- 기한이 늦을수록 더 낮은 우선순위를 부여받는다.
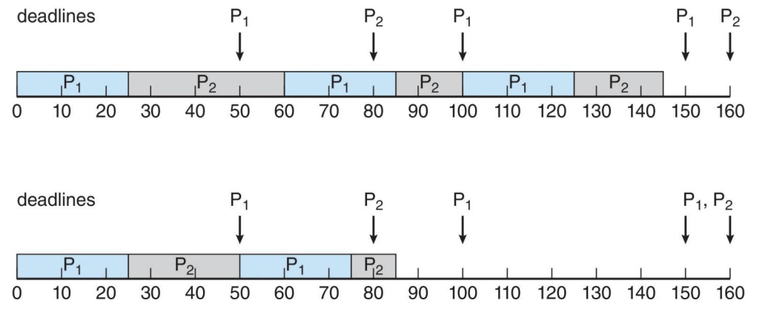
프로세스 주기 (Period) 처리 시간 (Processing Time) 마감 기한 (Deadline) P1 50 25 다음 주기가 시작되기 전까지 CPU 버스트를 완료해야 함 P2 80 35 다음 주기가 시작되기 전까지 CPU 버스트를 완료해야 함
4️⃣ 일정비율의 몫 스케줄링(Proportional Share Scheduling)
-
비례 분배 스케줄러(Proportional Share Scheduler)
- T개의 공유 자원이 시스템 내 모든 프로세스에 분배된다.
- 애플리케이션은 N개의 공유 자원을 받으며, 이때 N < T 여야 한다.
- 이를 통해 각 애플리케이션은 전체 CPU 시간에서 N / T 만큼의 시간을 할당받는다.
- 입장 제어 정책(admission-control policy) 과 함께 작동하여 애플리케이션이 할당된 모든 공유 자원을 받을 수 있도록 보장해야 한다.
-
예시
-
T = 100개의 공유 자원을 3개의 프로세스에 나누어 주는 경우:
- A: 50 shares, B: 15 shares, C: 20 shares
-
새로운 프로세스 D가 30 shares를 요청하면, 입장 제어기(admission controller) 는 D의 입장을 거부한다.
- 남은 공유 자원: 100 - (50 + 15 + 20) = 15
-