본 포스팅은 Abraham Silberschatz 저 『Operating System Concepts』(9th Edition)의 내용을 개인 학습 목적으로 요약·정리한 글입니다.
4.1 개요
-
스레드(Thread)는 CPU 이용의 기본 단위이다.
- 지금까지 프로세스가 단일 제어 스레드로 실행되는 프로그램이라고 가정하였으나, 실제 한 개의 프로세스에는 여러 제어 스레드가 포함될 수 있다.
-
스레드는 Thread ID, Program Counter, Register set, Stack으로 구성된다.
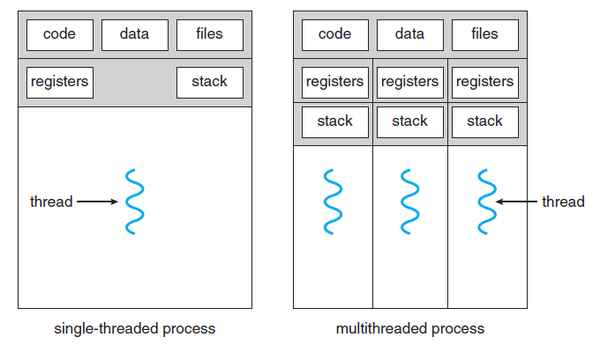
- Single Threaded process와 Multi-threaded process가 있다.
- 스레드는 같은 프로세스에 속한 다른 스레드와 Code, Data Section 등을 공유한다.
동기
- 현대의 대부분 애플리케이션은 멀티스레드(multi-threaded) 구조를 기반으로 동작한다.
-
여러 작업을 독립적인 스레드로 분리하여 동시에 처리할 수 있기 때문이다.
- 예를 들어, 웹 서버가 클라이언트로부터 HTML, 이미지, JS 등의 요청을 받는다.
- 만약 서버가 싱글스레드(single-threaded) 방식이라면, 한 번에 하나의 클라이언트 요청만 처리할 수 있어 병목이 발생한다.
- 이전 챕터까지는,
fork()를 통해 여러 프로세스를 생성하는 방법으로 이러한 문제를 해결했다. - 하지만, 프로세스는 각자 독립적인 주소 공간을 가지므로 생성/관리/문맥 전환 시 비용(오버헤드)이 크다.
- 스레드는 해당 문제를 해결할 수 있는 보다 효율적인 방법이다.
-
반면, 스레드는 하나의 프로세스 내부에서 생성되며, 주소 공간과 자원을 공유하므로 더 가볍고 빠른 단위의 병행 처리 수단으로 부각되었다.
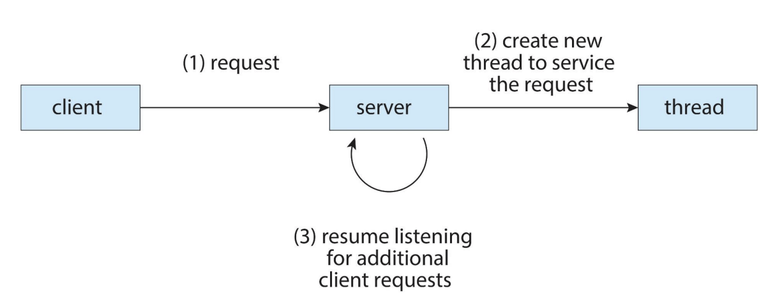
- 요청
- 요청을 서비스할 새로운 스레드를 생성한다
- (계속해서) 클라이언트 요청을 경청하는 작업을 재개한다.
- 코드 단순화 및 효율성 증대 가능
-
많은 운영체제의 커널은 현재 multi-threaded의 형태를 갖추고 있다.
- 커널 안에서 다수의 스레드들이 동작하고, 각 스레드는 인터럽트 처리 등 특정 작업을 수행한다.
스레드의 장점
- 반응성(Responsiveness) : 프로세스의 일부가 block되어도 계속 실행이 가능한다.
-
자원 공유(Resource Sharing) : 프로세스의 스레드들은 공유 메모리(shared-memory) 또는 메시지 전달(message-passing)보다 쉽게 자원 공유가 가능한다.
- 상기한 기법들은 (서로 다른 프로세스들이 힘겹게) 자원을 공유하는 방법이지만,
- 스레드는 자동적으로 (주소공간과 자원을) 공유하게 된다.
- 경제성(Economy) : 쓰레드 교환이 Context Switching보다 낮은 오버헤드를 가지고 프로세스 생성보다 생성 비용(메모리 등)이 낮다.
-
확장성/규모적응성(Scalability) : 멀티스레딩의 이점은 멀티 프로세서 구조에서 더욱 증가할 수 있다.
- 각각의 다른 스레드가 서로 다른 프로세서에서 Parallel하게 수행될 수 있기 때문이다.
멀티프로세싱 vs 멀티스레딩
질문 답변 둘 다 시분할 방식인가? ✅ OS가 CPU 시간을 나눠서 돌림 가장 큰 차이점은? ✅ 주소 공간과 자원 공유 여부 어느 쪽이 빠름? ✅ Thread (context switch 비용 적음) 어느 쪽이 안전함? ✅ Process (독립적이니까)
4.2 멀티코어 프로그래밍
- 다중 코어를 보다 효율적으로 사용하여 병행 실행(concurrency)을 더 향상할 수 있다.
-
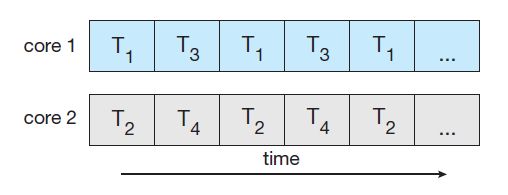
4개의 스레드로 실행되는 Application을 가정해보자:
-
하나의 코어는 한 번에 오직 하나의 스레드만 실행 가능하다 (=시분할)

병행 실행
- 다중 코어 시스템에서는 시스템이 개별 스레드를 각 코어에 배정할 수 있기 때문에 병행성이 증가한다.
-
병행(Concurrency) vs. 병렬(Parallelism)
개념 설명 환경 병행 (Concurrency) 겉으로 동시에 실행되는 것처럼 보이지만, 사실은 한 번에 하나씩 번갈아 실행됨 ✅ 싱글 코어 병렬 (Parallelism) 진짜로 여러 작업이 동시에 실행됨 ✅ 멀티 코어
프로그래밍 도전 과제
- 다중코어 시스템으로 발전하는 추세는 프로그래머에게도 새로운 도전이다.
-
일반적으로 multicore-based 프로그래밍하기 위해 아래 5개의 극복해야 할 도전과제가 있다
-
태스크 인식(Identifying Tasks)
- (독립적인 병행 가능한) 태스크를 나누어서 수행할 영역을 찾아야 한다.
-
균형 (Balance)
- 동일한 가치의 작업을 수행할 수 있도록 보장해야 한다.
-
데이터 분리 (Data Splitting)
- (영역을 나눈 것처럼) 태스크가 접근하는 데이터 또한 개별 코어에서 사용할 수 있도록 나누어져야 한다.
-
데이터 종속성 (Data Dependency)
- 태스크가 접근하는 데이터는 데이터는 둘 이상의 태스크 사이에 종속성이 없는지 검토되어야 한다. 만약 종속적인 경우, 종속성을 수용할 수 있도록 잘 동기화해야 한다.
- 이 부분은 6장(Syncronization)에서 다룬다.
-
시험 및 디버깅 (Testing and debugging)
- 단일 스레드 Application을 시험/디버깅하는 것보다 훨씬 어려움
-
병렬 실행의 유형(Types)
-
데이터 병렬 실행 (Data Parallelism)
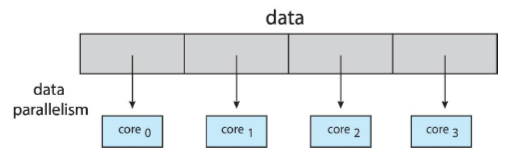
- 데이터에 초점을 맞추어, 데이터의 양을 동등하게 나누어 수행하게 함
-
태스크 병렬 실행 (Task Parallelism)
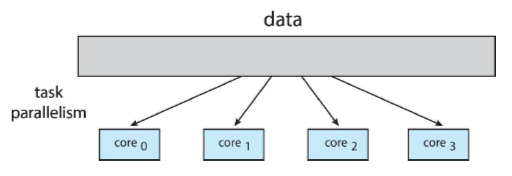
- 하는 일(서로 다른 연산)에 맞추어 각각 고유한 연산을 수행하게 함
- 요즘은 분산처리 시스템으로 인해 구분하지는 않는 추세
4.3 멀티스레드(Multithreading) 모델
-
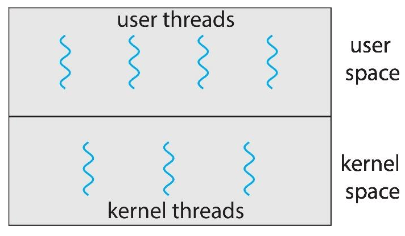
사용자 스레드와 커널 스레드의 차이
-
User thread (사용자 스레드)
- 용자 수준의 라이브러리(POSIX의 pthread, Java 라이브러리 등)를 통해 구현
- 사용자 스레드는 커널 위에서 지원되며 커널의 개입 없이 관리된다.
- POSIX Pthread, Win32 thread, Java thread 등
-
Kernel thread (커널 스레드)
- 운영 체제에서 직접 관리하고 지원함
- 거의 모든 운영체제들은 커널 쓰레드를 지원한다.
- Windows XP/2000, Solaris, Linux, Mac OS X 등
-
-
세 가지 모델
- Many-to-One model (다대일 모델)
- One-to-One model (일대일 모델)
- Many-to-Many model (다대다 모델)
1️⃣ 다대일(N:1) 모델
- Many-to-One Model
-
여러개의 사용자 수준 스레드를 하나의 커널 스레드에 매핑하는 모델
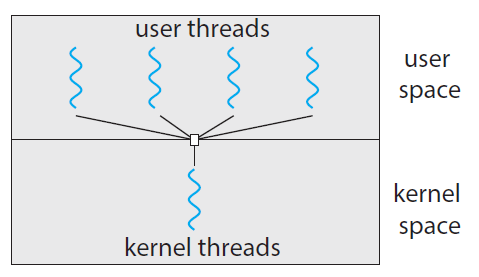
- 사용자 공간의 스레드 라이브러리에 의해 스레드가 관리되므로 효율적
-
커널의 시점에서는, 이 사용자 스레드들이 하나의 프로세스로만 보이게 된다.
- 커널 스케줄러는 ‘유저의 여러 스레드가 존재한다는 사실’을 전혀 모름
- 시스템이 멀티코어라고 하더라도, 다대일 방식은 이를 거의 활용하지 못함 (병렬 X)
-
그러나, 한 스레드가 Block 시스템콜을 할 경우, 매핑된 커널 스레드도 블록상태가 되어 전체 프로세스가 봉쇄된다.
- 일대일 : 모든 승객이 택시에 각자 탑승함. 누가 내려도 나머지는 제 갈길 감.
- 다대일 : 모든 승객이 버스에 함께 탑승함. 누가 내리면(Block) 모두 멈춰야 함.
2️⃣ 일대일(1:1) 모델
- One-to-One Model
-
각각의 사용자 스레드가 각각의 커널 스레드에 하나씩 매핑하는 모델
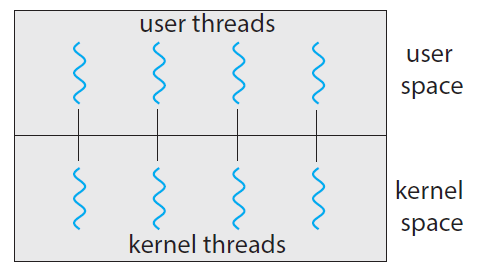
- 하나의 스레드가 각각 커널 스레드와 연결되어 있다
- 따라서 다대일(N:1) 모델의 ‘전체 봉쇄’ 문제가 발생하지 않는다. (다른 스레드는 여전히 수행됨)
- 단, 커널 스레드가 생성되기 때문에 오버헤드가 늘어 Application의 성능이 저하된다.
- 따라서 일대일 방식으로 구현된 대부분 OS는 시스템이 지원 가능한 스레드 수를 제한한다.
- 여러 개의 커널 스레드가 존재하여, 멀티코어에서 병렬로 수행될 수 있다.
- Windows, Linux 등의 운영체제가 일대일 모델을 활용한다.
3️⃣ 다대다(N:M) 모델
-
여러 개의 사용자 스레드를 그보다 작거나 같은 수의 커널 스레드로 매핑하는 모델
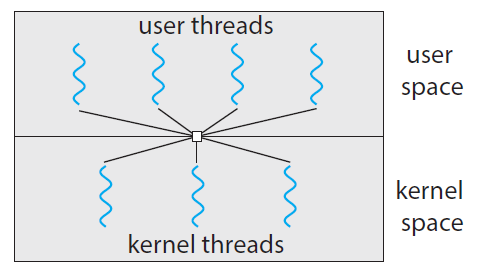
- 하나의 사용자 스레드가 Block 되어도 다른 사용자 스레드를 실행할 수 있음 (병렬성)
- 개발자가 필요한 만큼의 사용자 스레드를 생성할 수 있음
4️⃣ Two-level 모델
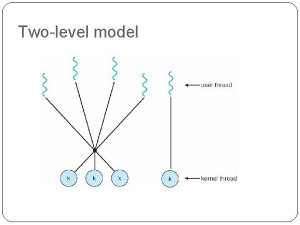
- 다대다 모델의 변형 방법
- 사용자 스레드를 적거나 같은 수의 커널 스레드로 매핑하는 규칙을 여전히 유지하지만,
-
원하면 특정 유저 스레드를 특정 커널 스레드에 바인딩(묶다? 고정시키다?)할 수 있도록 옵션을 제공한다.
- 특정 스레드가 ‘실시간 작업’을 요구할 때 → 커널에 직접 바인딩해야 지연 없이 처리 가능
- 바인딩되지 않은 유저 스레드 → 사용 가능한 커널 스레드를 스레드 라이브러리가 매핑
4.4 스레드 라이브러리
- 스레드 라이브러리는 프로그래머에게 Thread를 생성하기 관리하기 위한 API를 제공한다.
-
스레드 라이브러리를 구현하는 방법
-
커널의 지원 없이 (완전히 사용자 공간에서만) 라이브러리를 제공하는 방법
- 라이브러리의 모든 자원과 코드는 사용자 공간에 존재한다.
- 즉, 라이브러리의 함수를 호출 = 사용자 공간의 지역 함수를 호출한다는 것
-
OS에 의해 지원되는 (커널 수준에서의) 라이브러리를 구현하는 방법
- 모든 코드와 자료구조는 커널 공간에 존재
- 라이브러리 API를 호출하는 것은 커널 시스템콜을 부르는 것
-
스레드 예시
-
POSIX Pthreads
- 스레드의 동작에 관한 표준 (구현한 것은 아니나, 많은 시스템이 이를 구현함)
- API는 스레드 라이브러리의 동작을 정의하고, 구현은 라이브러리 개발자가 맡음
- 사용자 수준 또는 커널 수준으로 구현 가능
-
Java Thread
- JVM에서 관리
- 일반적으로 하위 운영 체제가 제공하는 스레드 모델을 사용하여 구현됨
동기화 스레딩 (Synchronous threading)
-
부모 스레드가 하나 이상의 자식 스레드를 생성한다. (
pthread_create())- 생성한 자식 스레드가 모두 종료할 때까지 기다렸다가 자신의 실행을 재개한다.
- 이 방식은 '포크-조인(fork-join)' 전략이라고 불린다.
pthread_create(...); // 자식 스레드 만들고 pthread_join(...); // 자식이 끝날 때까지 기다림 -
부모가 생성한 자식 스레드들은 병행적으로(concurrently) 실행된다.
- 부모는 자식들의 작업이 끝날 때까지 실행을 재개할 수 없다.
- 동기화 스레딩(Synchronous threading)은 상당한 양의 데이터를 공유하게 된다.
- 예를 들어, 부모 스레드는 자식들이 계산한 결과를 통합할 수 있어야 한다.
비동기 스레딩 (Asynchronous threading)
- 부모 스레드가 자식 스레드를 생성한 후, 부모는 자신의 실행을 재개하여 두 스레드를 병행하게 실행한다.
-
각 스레드는 모든 다른 스레드와 독립적으로 실행하기 때문에, 부모 스레드는 자식의 종료를 알 필요가 없다.
pthread_create(...); // 자식 생성 // 부모는 바로 자기 할 일 계속함 (pthread_join 없음) - 각 스레드들은 독립적이기 때문에, 스레드들 사이의 데이터 공유는 거의 없다.
4.5 암묵적 스레딩
- Implicit threading
- 개발자가 직접
pthread_create()같은 걸 호출하지 않고, 시스템이나 라이브러리가 자동으로 병렬 스레드를 생성하고 스케줄링하는 방식.
스레드 풀 (Thread Pool)
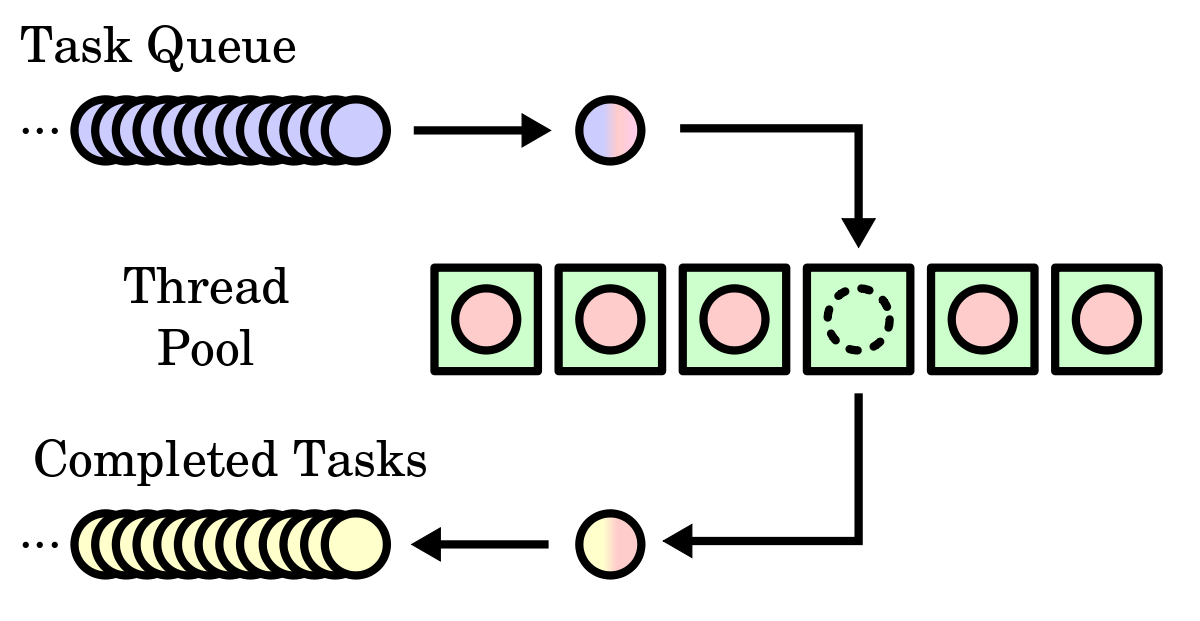
-
4.1 절에서의 웹 서버 예시를 상기해보자.
- 요청받을 때마다 새로운 스레드를 생성하는 것으로 병목 또는 오버헤드 문제를 개선했다.
- 그러나, 새로운 스레드를 만드는 것 또한 일정 시간이 소요된다.
- 언젠가 새로운 스레드를 생성할 자원(CPU, 메모리 등)이 고갈될 수도 있다.
-
스레드 풀은 프로세스를 시작할 때, 일정한 수의 스레드를 미리 풀(Pool)로써 만들어놓는 것
- 풀 속 스레드들은 일(work)을 계속 기다린다.
- request가 들어오면, 풀에 있는 하나의 스레드에 요청을 할당한다.
- 만약 여유 스레드가 없다면, 서버는 가용 스레드가 하나 남을 때까지 기다린다.
-
스레드 풀의 장점
- 새 Thread를 만들어 주는 것보다 생성된 Thread를 사용하여 서비스해 주는 것이 더 빠르다.
- Thread pool은 임의의 시간에 존재할 수 있는 Thread 개수에 제한을 둔다.
- task를 생성하는 방법을 분리하여, task를 일정 시간 후에 실행되도록 하거나, 주기적으로 실행시킬 수 있다.
4.6 스레드와 관련된 문제들
#️⃣ 스레드의 fork() 및 exec() 시스템콜 문제
-
fork()
-
fork()시스템 콜을 호출하면 새로운 프로세스 공간을 별도로 생성해야 한다.- fork() 시스템 콜을 호출한 부모 프로세스 공간의 데이터들을 자식으로 모두 복사한다.
-
멀티스레드 프로세스 환경에서 하나의 스레드가
fork()를 수행하게 된다면?- 부모 프로세스가 사용하는 모든 스레드를 복사함
- 부모 프로세스에서 fork()를 호출한 스레드 하나만 복사함
- 위 두가지 버전의 fork() 중 어떤 것을 선택할지는 Application에 달려 있다.
-
-
exec()
-
자식 프로세스가 새로운 프로그램을 실행하는 시스템 콜
- exec() 시스템 콜을 호출한 현재 프로세스 공간의 TEXT, DATA, BSS 영역을 새로운 프로세스의 이미지로 대체
- 따라서 별도의 프로세스 공간을 생성하지 않고 exec()의 매개변수로 지정한 프로세스로 대체
-
-
만약 어떤 프로세스안의 쓰레드가 fork()를 호출한 다음 exec()를 호출한다면 어떻게 설계하는게 좋은가?
- 1번의 경우, 자식이 부모의 모든 쓰레드를 복사한 후 exec() 호출하여 새로운 프로세스로 대체됨.
- 2번의 경우, fork()를 호출한 쓰레드만 복사된 다음 exec()를 호출하여 새로운 프로세스로 대체됨.
- 오버헤드가 더 적은 2번이 적절하다.
#️⃣신호 처리(Signal Handling)
-
신호: 어떤 사건이 일어났음을 알려주기 위해 사용되는 것
- 동기식 신호 : DivideByZero, 메모리 불법적 접근 등의 행동으로 발생
- 비동기식 신호 : Ctrl+C를 눌러 쉘 종료와 같은 외부의 행동으로 발생
-
신호 처리기
- 디폴트 신호 처리기: 모든 신호마다 커널에 의해 실행되는 처리기
- 사용자 정의 처리기 : 특정 신호에 사용자가 정의한 방식으로 처리되는 처리기
-
다중 스레드 프로그램에서의 신호 처리
-
어느 스레드에게 신호를 전달해야 하는가?
- 신호가 전달될 스레드에게만 전달 (단일)
- 모든 스레드에 전달
- 몇몇 스레드에게만 선택적으로 전달
- 특정 스레드가 모든 신호를 전달받도록 지정
-
동기식 신호의 경우 → 일반적으로 1번 (신호가 전달될 스레드에게만 전달)
- 따로 선택할 수 없고, 에러 발생과 동시에 전달됨
-
비동기식 신호의 경우 → 일반적으로 … 글쎄. 3이나 4번?
- 누가 받을지 개발자가 선택할 수 있음.
-
#️⃣ 취소 (Cancellation)
-
스레드가 채 끝나기 전에 그것을 강제 종료시키는 행위
- DB 병렬 검색 중 어떤 스레드가 결과를 찾아냄. → 나머지 스레드를 취소해야 함
- 이 때, 취소당하는 스레드를 목적 스레드(target threads)라고 부른다.
-
스레드 취소의 두 가지 방식
-
비동기 취소(Asynchronous cancellation): 어느 스레드가 즉시 목적 스레드를 강제 종료
- 할당된 자원을 올바르게 해제하지 못할 수 있음
-
지연 취소(Deferred cancellation): 목적 스레드가 주기적으로 자신이 강제 종료되어야 할지 여부를 점검함.
- 스레드들은 자신이 취소되어도 안전하다고 판단되는 시점에 취소 여부를 검사할 수 있다
-
pthread_cancel()의 기본 설정은 지연 취소 방식이다.- 취소는 스레드가 취소점(cancellation point)에 도달했을 때에만 취소 작업 실행
- 취소점을 만드는 방법은 pthread_testcancel() 함수를 호출하는 것이다.
- 취소 요청이 대기중이라는 것이 발견되면, 정리 처리기(cleanup handler)가 스레드 종료 이전에 스레드의 모든 자원을 반환하도록 한다. ![[image-1.png]]
-
#️⃣ 스레드 국지 저장소(Thread-Local Storage)
- 한 프로세스에 속한 스레드들은 그 프로세스의 data를 모두 공유한다.
- 그러나, 상황에 따라 각 스레드는 자신만이 접근할 수 있는 데이터를 가져야 할 수도 있다.
-
이러한 data를 TLS(스레드 국지 저장소)라고 부른다.
- Windows, Linux, Java 등 모든 스레드 라이브러리는 어떤 형태로든 TLS를 지원한다.
지역 변수 vs. TLS
- 지역 변수는 하나의 함수가 호출되는 동안에만 보인다.
- TLS는 전체 함수 호출에 걸쳐 보인다.
#️⃣ 스케줄러 액티베이션(Scheduler Activation)
-
LWP(Lightweight Process)
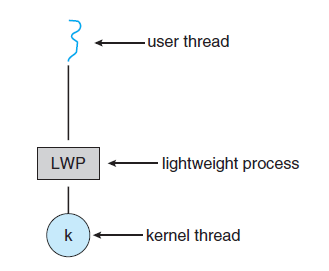
- 멀티스레딩 프로그램에서는 스레드 라이브러리와 커널과의 통신을 고려해야 한다.
-
다대다(N:M) 또는 Two-Level 모델을 구현한 대부분의 시스템은 사용자와 커널 스레드 사이에 중간 자료 구조를 둔다.
- Application에 할당된 커널 스레드의 수를 적절하게 유지해야 하기 때문
-
이 자료구조를 LWP(Lightweight Process, 경량 프로세스) 라고 한다.
- 유저 스레드와 커널 스레드 사이의 연결 다리 역할을 한다.
- 하나의 LWP는 하나의 커널 스레드에 속한다.
- 따라서, 커널 스레드가 Block되면 LWP 역시 함께 Block된다.
| 이유 | 설명 |
|---|---|
| 1️⃣ 유연한 매핑 관리 | 유저 스레드를 커널 스레드에 직접 매핑하면 변경이 어려움. → LWP를 두면 N개의 유저 스레드를 M개의 LWP에 자유롭게 매핑 가능. |
| 2️⃣ 스케줄링 자유도 확보 | 커널은 LWP 단위로 스케줄링만 하면 되고, 유저 스레드 간의 스케줄링은 사용자 라이브러리가 LWP 위에서 관리함. |
| 3️⃣ 블로킹 시스템 콜 문제 해결 | 어떤 LWP가 block되어도, 다른 LWP는 계속 동작 가능 → 전체가 멈추는 다대일(M:1) 문제 해결 |
| 4️⃣ 신호 전달 등의 커널 이벤트 대응 | 커널은 LWP에 신호 전달 → LWP가 매핑된 유저 스레드로 전달. (중간 계층이 있어야 매핑이 자연스럽게 이루어짐) |
| 5️⃣ 동시성 증가와 커널 리소스 절감의 절충 | 모든 유저 스레드를 커널 스레드로 만들면 리소스 소모 큼. → 적당한 수의 LWP만 만들고 그 위에 여러 스레드 배치하면 효율적. |
-
스케줄러 액티베이션
- 사용자 스레드 라이브러리와 커널 스레드 간 통신을 하는 방법
-
스케줄러 액티베이션의 이유
- 커널은 커널 스레드에 대해 인지할 수 있지만,
- Application은 커널 스레드에 대헤 알고 있는 정보가 부족하다.
- 응용 프로그램과 커널 사이에 정보를 원할히 교환할 할 수 있는 방법
-
스케줄러 액티베이션 방법
- 커널은 응용 프로그램에게 가상 처리기(LWP)의 집합을 제공함
- LWP의 집합을 받은 응용 프로그램은 사용자 쓰레드를 사용이 가능한 가상 처리기로 스케줄링함
-
사용자 쓰레드가 수행 도중 커널은 응용 프로그램에게 특정 사건에 대한 메시지를 보냄 (upcall)
- upcall은 커널이 응용 프로그램에게 특정 사건에 대한 메시지를 보내는 행위를 의미함 (반대로 응용 프로그램이 커널에게 메시지를 보내는 것을 system call이라고 함)
- upcall은 쓰레드 라이브러리에 존재하는 upcall 처리기에 의해 처리됨
- upcall 처리기는 가상 처리기에서 실행됨
- 응용 프로그램은 커널로부터 새로운 가상 처리기를 할당받음.
- 가상 처리기 위에서 upcall 처리기를 실행함
- upcall 처리기는 봉쇄 쓰레드의 상태 저장 및 봉쇄 쓰레드가 실행중이던 가상 처리기를 반환
- upcall 처리기는 실행 가능한 다른 커널 쓰레드를 스케줄링
-
예를 들어 upcall을 일으키는 특정 사건을 예시로 든다면 upcall은 사용자 쓰레드가 봉쇄(입/출력같은 이벤트)하려고 할때 발생할 수 있다. 이때 upcall을 처리하는 과정은 다음과 같다.
- 사용자 쓰레드가 봉쇄되려고 할때 커널은 쓰레드가 봉쇄하려고 한다는 사실과 그 쓰레드의 식별자를 알려주는 upcall을 수행함
- 커널은 새로운 가상 처리기(LWP)를 응용 프로그램에게 할당함
- 응용 프로그램은 새로 할당 받은 가상 처리기에서 upcall처리기를 올려두고 수행함
- upcall 처리기는 봉쇄 쓰레드의 상태를 저장하고 봉쇄 쓰레드가 실행중이던 가상 처리기를 반환함
- upcall 처리기는 새로운 가상 처리기에서 실행 가능한 다른 커널 쓰레드를 스케줄링함
- 봉쇄 쓰레드가 기다리던 사건이 발생하면 커널은 이전에 봉쇄되었던 사용자 쓰레드가 이제 실행 가능하다는 사실을 알려주는 또 다른 upcall을 쓰레드 라이브러리에게 전송함
- 또 다른 upcall을 처리하기 위해서 커널은 새로운 가상 처리기를 할당한 다음 사용자 쓰레드를 하나 할당하여 새로운 가상 처리기에서 upcall 처리기를 실행함
- 봉쇄가 풀린 쓰레드를 실행 가능 상태로 표시한 후에 응용 프로그램은 사용 가능한 가상 처리기 상에서 다른 실행 가능한 쓰레드를 실행한다.