그래프 탐색
이전 글에서 시간 복잡도를 설명하며 선형 탐색과 이진 탐색에 대해 다루었다. 두 알고리즘 모두 선형적 구조에서 작동하는 탐색 방식으로, 그래프 탐색은 비선형적 구조를 탐색하는 알고리즘이며 조금 다른 접근 방식이 필요하다.
그래프 이론
그래프는 노드(Node, 또는 Vertex)와 간선(Edge)으로 이루어진 비선형 자료 구조이다. 노드는 객체의 개념으로, 간선은 노드들 간의 관계나 연결을 나타낸다.
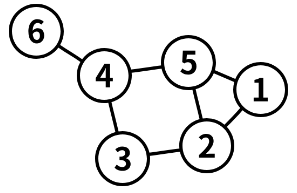
노드는 주로 문제에서 사람, 도시, 편의점 등 우리가 모델링하고자 하는 객체를 의미한다. 이들 사이를 연결하는 ‘관계’가 바로 간선으로, 간선은 도시를 이어주는 도로일 수도 있고, 사람 간의 친분을 나타낼 수도 있다.
그래프와 탐색
그래프를 탐색하는 알고리즘에는 대표적으로 DFS와 BFS가 있다. DFS는 깊이 우선 탐색으로, 그래프/트리의 가장 깊은 곳을 우선 탐색하는 알고리즘이다. 갈 수 있는 한계까지 도달해 결국 트리의 말단 노드(Leaf node)에 우선 도달하게 된다.
BFS는 너비 우선 탐색으로, 그래프/트리의 탐색 시작 노드의 가장 가까운 노드부터 탐색하는 알고리즘이다. 방문한 노드의 인접 노드 중 방문하지 않은 노드는 모두 순차적으로 방문한다.
그렇다면 DFS와 BFS는 각각 왜, 언제 써야할까?
- 최단 거리를 구해야 할 때: BFS가 유리하다. BFS가 가장 먼저 도달한 노드가 최단 경로를 보장하기 때문이다. 미로 찾기와 같은 문제에서 BFS는 시작점에서 인접한 노드를 먼저 탐색하고, 차례차례 레벨을 늘려가며 탐색하므로, 처음으로 목표 지점에 도달할 때 그 경로가 최단 경로임을 보장한다.
- 경로의 구성요소가 중요할 때: DFS가 유리하다. 예를 들어, 특정 조건을 만족하는 경로를 찾는 문제에서는 DFS가 각 경로를 끝까지 따라가며 조건을 확인할 수 있어 유리하다.
- 그래프의 모든 정점을 방문해야 할 때: DFS/BFS 모두 사용 가능하다. 단, 두 방식 모두 조건 내의 모든 노드를 검색한다는 점에서 시간 복잡도는 동일하지만 일반적으로 DFS를 재귀 함수로 구현한다는 점에서 DFS보다 BFS가 조금 더 빠르게 동작할 수 있다.
DFS
DFS(Depth-First Search, 깊이 우선 탐색)는 그래프나 트리 구조에서 깊이를 우선적으로 탐색하는 알고리즘이다. 이 알고리즘은 가능한 한 깊숙이 들어가며 탐색을 진행하고, 더 이상 진행할 수 없게 되면 이전 노드로 되돌아가서 다시 탐색을 이어간다. 이렇게 탐색을 진행하는 방식은 스택을 활용하는 방식으로 구현된다.
DFS는 다음의 동작 과정을 거친다.
- 탐색 시작 노드를 스택에 삽입하고, 방문 처리
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고, 방문 처리
- 위 과정을 더 수행할 수 없을 때까지 반복
스택을 사용하는 이유
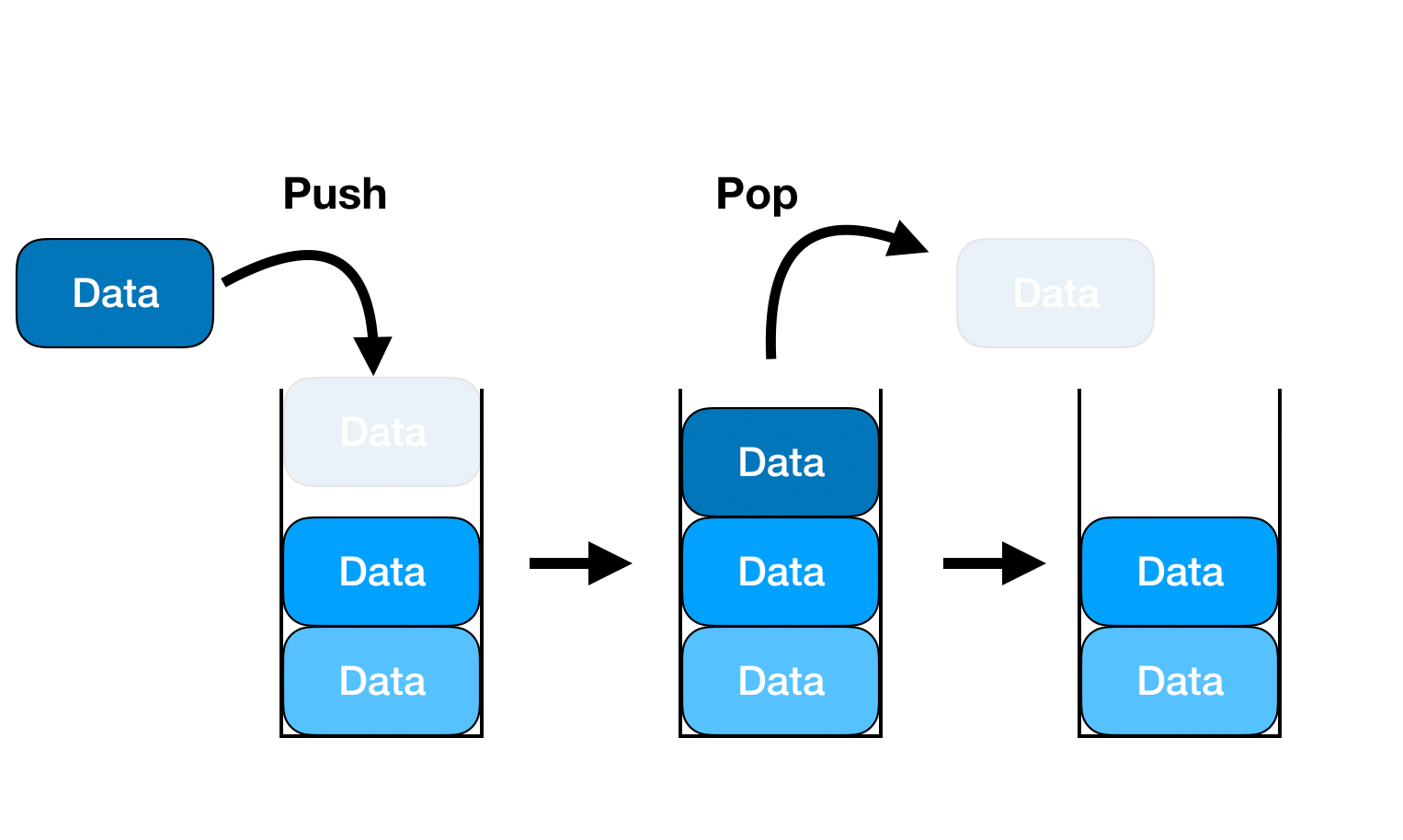
DFS는 가능한 한 깊게 탐색한 후, 더 이상 진행할 수 없으면 이전 노드로 되돌아가서 다른 경로를 탐색하는 방식으로 작동한다. 이때, 가장 마지막에 넣은 자료를 가장 먼저 꺼내는 스택(Last In, First Out, LIFO) 자료구조가 필요하다.
스택을 가장 쉽게 경험할 수 있는 예시가 바로 브라우저의 방문 기록이다. 인터넷을 탐색하다가 이전 페이지로 돌아가고 싶을 때, "뒤로 가기" 버튼을 누른다. 이때, 가장 최근에 방문한 페이지부터 차례대로 돌아가게 되는데, 이는 하이퍼링크를 클릭할 때마다 스택에 페이지가 하나씩 쌓여 왔기 때문이다.
DFS 예시 코드
result = []
def dfs(graph, v, visited):
visited[v] = True # 현재 노드를 방문 처리
result.append(v) # 결과에 현재 노드 저장
for i in graph[v]: # 현재 노드의 인접 노드를 하나씩 불러오기
if visited[i] == False: # 방문하지 않았다면
dfs(graph, i, visited) # 재귀 호출 ( -> Leaf까지 곧바로 도달)
graph = [ ... ] # 그래프 정보 입력받기
visited = [False] * 9
dfs(graph, 1, visited)
print(*result)BFS
BFS(Breadth-First Search, 너비 우선 탐색)는 그래프나 트리 구조에서 너비를 우선적으로 탐색하는 알고리즘이다. 이 알고리즘은 시작 노드에서부터 인접한 노드를 차례로 탐색하고, 각 레벨을 한 번에 탐색한 후 그다음 레벨로 이동하는 방식으로 진행된다. BFS는 큐 자료구조를 사용하여 구현된다.
BFS는 다음의 동작 과정을 거친다.
- 탐색 시작 노드를 큐에 삽입하고, 방문 처리
- 큐에서 노드를 꺼내어 그 노드의 인접한 방문하지 않은 노드를 모두 큐에 삽입하고, 방문 처리
- 위 과정을 큐가 빌 때까지 반복
큐를 사용하는 이유
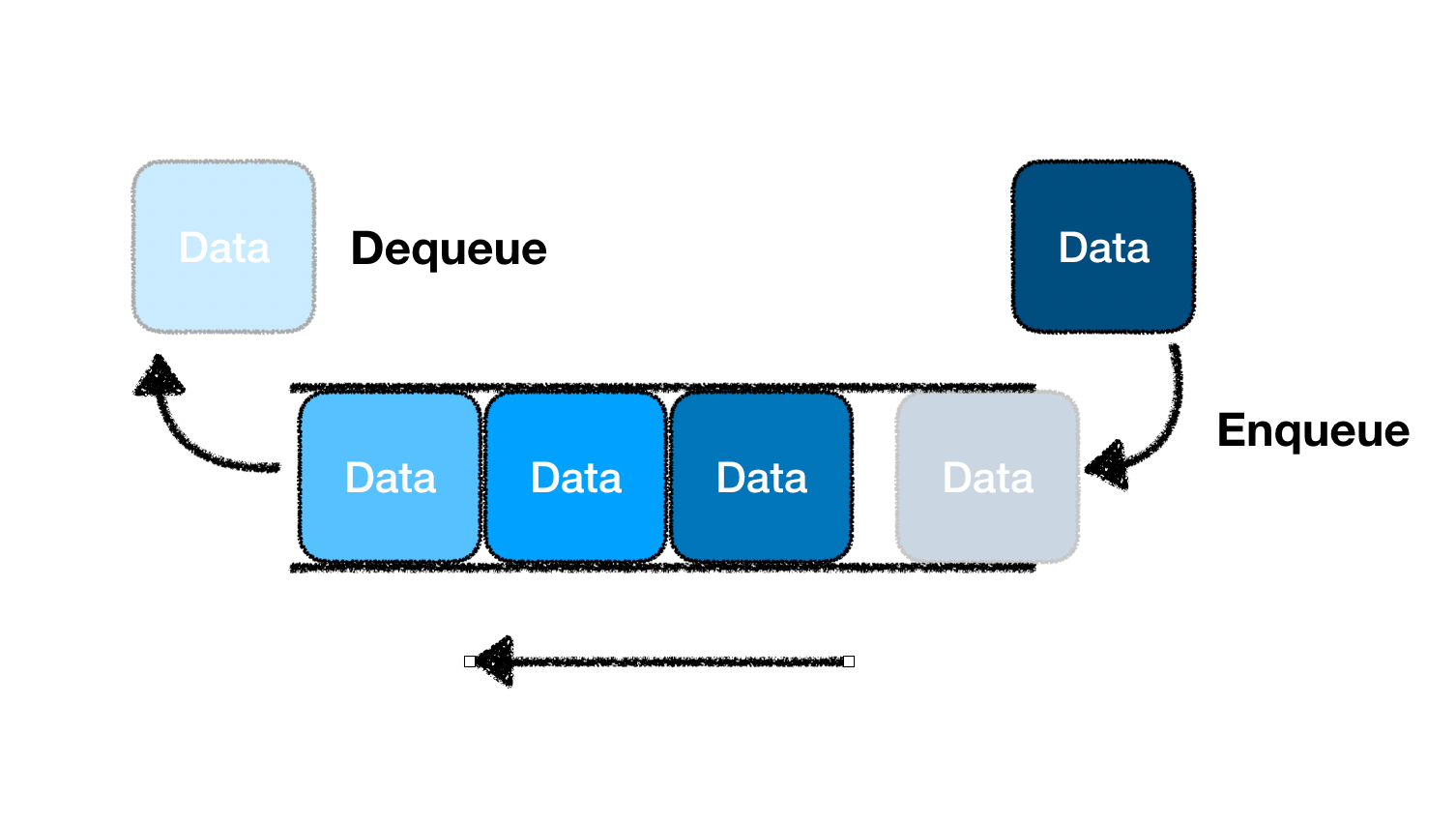
BFS는 인접한 노드를 먼저 탐색하고, 그다음 레벨로 차례대로 이동하는 방식으로 작동한다. 이때, 큐(First In, First Out, FIFO) 자료구조가 필요하다. 큐는 먼저 들어간 자료를 먼저 꺼내는 특징이 있어, BFS에서 각 레벨을 순차적으로 탐색할 수 있도록 도와준다.
큐를 가장 쉽게 경험할 수 있는 예시가 바로 대기열이다. 예를 들어, 은행에 사람이 줄 서서 기다릴 때, 먼저 온 사람이 먼저 서비스를 받는 방식이다. 이때 대기열에서 첫 번째로 들어온 사람이 첫 번째로 나가게 되며, 이는 큐의 원리와 동일하다.
deque(데크)
파이썬의 리스트는 기본적으로 큐(queue)와 같이 동작할 수 있다. 그러나, 파이썬에서 BFS를 구현할 때 list 대신 deque를 사용하는 이유는 list의 pop(0) 연산이 비효율적이기 때문이다.
list에서pop(0)을 사용하면 첫 번째 요소를 꺼낼 때, 나머지 모든 요소를 한 칸씩 앞으로 당겨야 하므로 O(n) 시간이 걸린다. 이는 BFS에서 큐의 앞에서 요소를 계속 꺼내는 작업이 많기 때문에 성능에 큰 영향을 미친다.- 반면,
deque(double-ended queue)는 양쪽 끝에서 요소를 삽입하거나 삭제하는 데 O(1) 시간이 걸린다. 그래서 큐에서 앞에서 요소를 빼고 뒤에 추가하는 작업이 매우 효율적이다.
따라서 BFS 구현 시 deque를 사용하면 큐 연산을 효율적으로 처리할 수 있어 성능이 크게 향상된다.
BFS 예시 코드
from collections import deque
result = []
def bfs(graph, start, visited):
q = deque([start]) # 큐(방문할 노드의 순서 대기열)에 시작 노드를 삽입함
visited[start] = True # 시작 노드를 방문 처리
while q: # 큐에 노드가 남아있을 경우
v = q.popleft() # 대기열 맨 앞의 노드를 제거 후 현재 노드로 설정
result.append(v) # 결과에 현재 노드 저장
for i in graph[v]: # 현재 노드의 인접 노드를 하나씩 불러오기
if not visited[i]: # 방문하지 않았다면
q.append(i) # 큐에 현재 노드 삽입
visited[i] = True # 현재 노드 방문처리
graph = [ ... ] # 그래프 정보 입력받기
visited = [False] * 9
bfs(graph, 1, visited)
print(*result)추천 문제
바이러스 (실버 3)
- https://www.acmicpc.net/problem/2606
- 인접 리스트 방식의 가장 기본적인 그래프 탐색 문제
단지 번호 붙이기 (실버 1)
- https://www.acmicpc.net/problem/2667
- 인접 행렬 방식의 입력이 제공되며, 가장 자주 출제되는 형태의 탐색 문제
DFS와 BFS (실버 2)
- https://www.acmicpc.net/problem/1260
- DFS와 BFS를 모두 익히기에 적합
전쟁 - 전투 (실버 1)
- https://www.acmicpc.net/problem/1303
- 탐색 응용 문제
적록색약 (골드 5)
- https://www.acmicpc.net/problem/2206
- 탐색 응용 문제. 약간의 구현(Implementation) 기법이 필요하다.
벽 부수고 이동하기 (골드 3)
- https://www.acmicpc.net/problem/2206
- 난이도 있는 너비 우선 탐색 문제